OceanBase连接顺序选择的优劣评估

一、目的
在OLAP场景中,多表连接是十分常见的,查询的执行效率跟它涉及的表的连接顺序息息相关。以A、B、C三张表为例,有一条查询:SELECT * FROM A, B, C WHERE …,那么这三张表的连接顺序可以是(A⋈B)⋈C、(A⋈B)⋈C、(A⋈C)⋈B等共6种连接顺序,我们将全部连接顺序称为搜索空间。不同的连接顺序是语义等价的,即能获得相同的结果集,但是对于查询效率有着非常大的影响。从搜索空间中选出性能最优的连接顺序是一个关键的DBMS优化问题,但是随着连接表数量的增加,搜索空间的大小呈指数级增长,这使得连接顺序选择成为一个NP-hard问题。本文主要评测OceanBase连接顺序选择策略的优劣,以分析OceanBase对多表连接查询的处理能力以及优化空间。
二、OceanBase查询计划分析
为了得到OceanBase执行某查询时选择的连接顺序,我们需要分析该查询的执行计划,具体方法如下。
2.1 EXPLAIN关键字
OceanBase可以利用EXPLAIN关键字得到查询的执行计划。
- 示例:
obclient> explain select count(*) from table_0, table_6, table_5, table_3 where table_0.fk_0 = table_6.primaryKey and table_0.fk_1 = table_5.primaryKey and table_0.fk_3 = table_3.primaryKey and table_0.col_0 > 10000 and table_5.col_6 > 10000 and table_6.col_3 > 10000 and table_3.col_2 > 10000; | Query Plan =================================================== |ID|OPERATOR |NAME |EST. ROWS|COST | --------------------------------------------------- |0 |SCALAR GROUP BY | |1 |15299| |1 | HASH JOIN | |334 |15236| |2 | PX COORDINATOR | |338 |11647| |3 | EXCHANGE OUT DISTR|:EX10000|338 |11519| |4 | HASH JOIN | |338 |11519| |5 | HASH JOIN | |341 |6906 | |6 | TABLE SCAN |table_3 |400 |3148 | |7 | TABLE SCAN |table_0 |344 |2932 | |8 | TABLE SCAN |table_6 |452 |3580 | |9 | TABLE SCAN |table_5 |313 |2486 | =================================================== Outputs & filters: ------------------------------------- 0 - output([T_FUN_COUNT(*)]), filter(nil), group(nil), agg_func([T_FUN_COUNT(*)]) 1 - output([1]), filter(nil), equal_conds([table_0.fk_1 = table_5.primaryKey]), other_conds(nil) 2 - output([table_0.fk_1]), filter(nil) 3 - output([table_0.fk_1]), filter(nil), is_single, dop=1 4 - output([table_0.fk_1]), filter(nil), equal_conds([table_0.fk_0 = table_6.primaryKey]), other_conds(nil) 5 - output([table_0.fk_1], [table_0.fk_0]), filter(nil), equal_conds([table_0.fk_3 = table_3.primaryKey]), other_conds(nil) 6 - output([table_3.primaryKey]), filter([table_3.col_2 > 10000]), access([table_3.primaryKey], [table_3.col_2]), partitions(p0) 7 - output([table_0.fk_0], [table_0.fk_1], [table_0.fk_3]), filter([table_0.col_0 > 10000]), access([table_0.fk_0], [table_0.fk_1], [table_0.fk_3], [table_0.col_0]), partitions(p0) 8 - output([table_6.primaryKey]), filter([table_6.col_3 > 10000]), access([table_6.primaryKey], [table_6.col_3]), partitions(p0) 9 - output([table_5.primaryKey]), filter([table_5.col_6 > 10000]), access([table_5.primaryKey], [table_5.col_6]), partitions(p0) | -
EXPLAIN输出的第一部分是查询执行计划的树形结构,第二部分是各个算子的详细信息。在第一部分中,ID表示查询执行树按照前序遍历的方式得到的编号,OPERATOR表示算子的名称,NAME表示操作涉及的表名,EST.ROWS表示该算子的估算中间结果行数,COST表示该算子的执行代价。
- 在OPERATOR一列,每一个操作算子以缩进的形式表示其在树中的层次,层次深的算子先执行。以上面的查询执行计划为例:最先执行ID为6的TABLE SCAN算子和ID为7的TABLE SCAN算子,再执行ID为5的HASH JOIN操作,即先扫描表table_3和table_0,再对它们进行hash join。上层操作以此类推,最终得到的连接顺序为
((table_3⋈table_0)⋈table_6)⋈table_5。
2.2 查询执行树
-
当查询涉及的表增多,我们可能无法一目了然地从EXPLAIN的查询计划中得到当前的连接顺序。因此,我们利用图形化的方式,将EXPLAIN的查询执行计划画成对应查询执行树,以更形象地展示各表的连接顺序。为了简化查询执行树,树上的节点只包含scan和join类型。
-
我们利用DOT语言来实现以上目的,DOT语言是一种文本图形描述语言,语法相对简单。
-
2.1节示例的DOT描述如下:
digraph binaryTree{ "1_HASH_JOIN"->"4_HASH_JOIN";"1_HASH_JOIN"->"table_5"; "4_HASH_JOIN"->"5_HASH_JOIN";"4_HASH_JOIN"->"table_6"; "5_HASH_JOIN"->"table_3";"5_HASH_JOIN"->"table_0"; } -
命令:
dot -Tpng example.dot -o example.png -
生成简化的查询执行树为:

三、实验设计
3.1 实验流程
- 实验流程图如下:
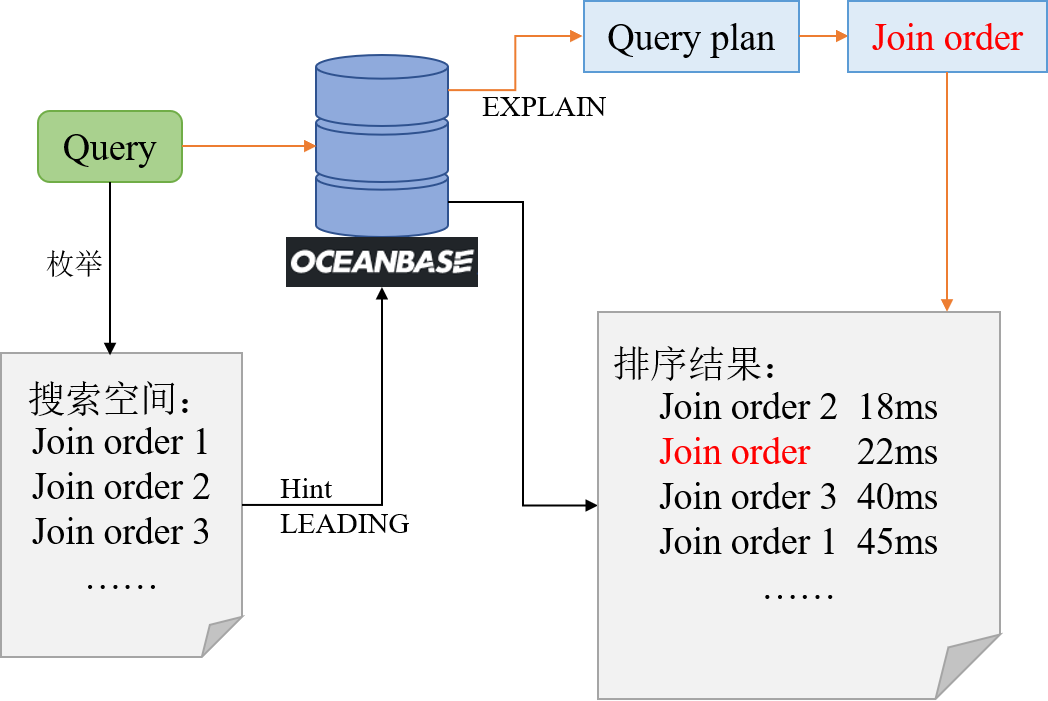
-
对于每一个查询,我们枚举它所有可能的连接顺序,并利用hint关键字LEADING,强制OceanBase以特定连接顺序执行查询。
-
我们得到查询的所有连接顺序及其对应执行时间,从而得到OceanBase所选连接顺序在搜索空间中的排名情况。
-
示例:
-
query: SELECT * FROM A, B, C WHERE A.id = B.id AND A.id = C.id; -
hint关键字_LEADING_应用举例:
SELECT /*+LEADING(A, B, C)*/ FROM A, B, C WHERE A.id = B.id AND A.id = C.id;表示强制以
(A⋈B)⋈C的顺序执行查询。 -
按照执行时间由小到大将连接顺序排序:
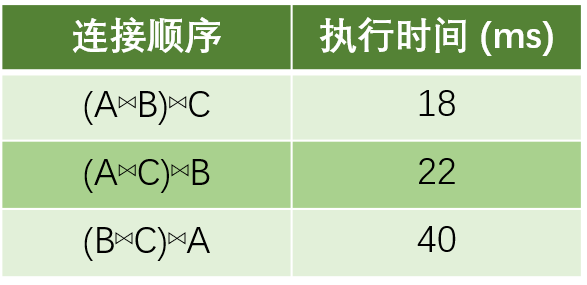
- 其中OceanBase所选的连接顺序为(A⋈C)⋈B,则其排名为2。
-
-
注意:由于随着连接的表数量增加,搜索空间的大小呈指数级增长,如6张表的搜索空间为720,7张表的搜索空间为5040,8张表的搜索空间为40320……因此想让数据库执行搜索空间中每一个连接顺序是十分耗时的。在实验中,当搜索空间大于100时,我们将OceanBase选择的连接顺序作为一个候选项放入评估池,在搜索空间中再随机选择100个连接顺序,共101个评估对象;然后我们评估OceanBase选择的连接对象在101个评估对象中的相对位置,实现对OceanBase多表join的效果评估。
3.2 评价指标
-
Mean Reciprocal Rank (MRR)
-
在检索系统中,MRR值表示正确检索结果值在检索结果中的排名,用来评估检索系统的性能。
-
公式:
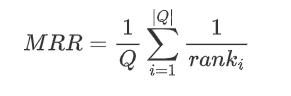
其中,|Q| 是query的个数,*ranki* 是对于第*i*个query,OB选择的连接顺序的执行时间在所有连接顺序执行时间中的排列位置(从小到大)。 * 举例:

得到 MRR值为:
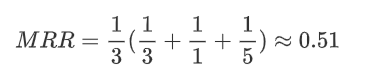
-
-
Deviation 偏差
-
计算优化器所选连接顺序的执行时间与最优执行时间之间的偏差。
-
公式:
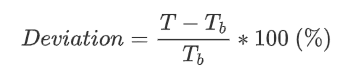
其中,T 表示优化器所选连接顺序的执行时间,Tb 表示枚举的连接顺序搜索空间中最优(最短)的执行时间。
-
四、实验配置
4.1 机器配置
-
本次实验将OceanBase部署在4台机器上,机器配置如下:

4.2 集群配置
-
OceanBase数据库部署的配置文件如下:
user: username: xxx password: xxx # key_file: .ssh/authorized_keys oceanbase-ce: version: 3.1.2 servers: - name: host1 ip: 10.24.14.55 - name: host2 ip: 10.24.14.228 - name: host3 ip: 10.24.14.111 global: devname: eth0 cluster_id: 1 memory_limit: 28G system_memory: 8G stack_size: 512K cpu_count: 16 cache_wash_threshold: 1G __min_full_resource_pool_memory: 268435456 workers_per_cpu_quota: 10 schema_history_expire_time: 1d net_thread_count: 4 major_freeze_duty_time: Disable minor_freeze_times: 10 enable_separate_sys_clog: 0 enable_merge_by_turn: FALSE datafile_disk_percentage: 35 syslog_level: WARN enable_syslog_recycle: true max_syslog_file_count: 4 appname: obct host1: mysql_port: 3883 rpc_port: 3882 home_path: /data/obdata1 zone: zone0 host2: mysql_port: 3883 rpc_port: 3882 home_path: /data/obdata1 zone: zone1 host3: mysql_port: 3883 rpc_port: 3882 home_path: /data/obdata1 zone: zone2 obproxy: servers: - 10.24.14.188 global: listen_port: 3883 home_path: /data/obproxy1 rs_list: 10.24.14.55:3883;10.24.14.228:3883;10.24.14.111:3883 enable_cluster_checkout: false cluster_name: obct
4.3 实验数据
- 本实验采用随机生成的数据和负载,并且保证所有实验负载的有效性,即负载中的每个算子均有返回结果集。
-
表规模:
- 每次生成16张表,其中40%的表有1,000~5,000行数据(约500KB),30%的表有10,000~50,000行数据(约6MB),30%的表有100,000~500,000行数据(约140MB)。
-
查询:
- 分别针对3、4、5、6、7、8张表的连接,各随机生成100条不同的查询。
-
-
实验数据获取地址
4.4 注意点
- 为避免查询计划缓存对实验结果的影响,我们将系统变量ob_enable_plan_cache 设置为 FALSE ,表示 SQL 请求不可以使用计划缓存。
五、实验结果展示与分析
5.1 实验结果
-
下表展示了3~8张表连接时的MRR值。

同时,我们也在TiDB上进行了3 join 与4 join的实验,得到的MRR值分别为0.35与0.22,明显劣于OceanBase。
-
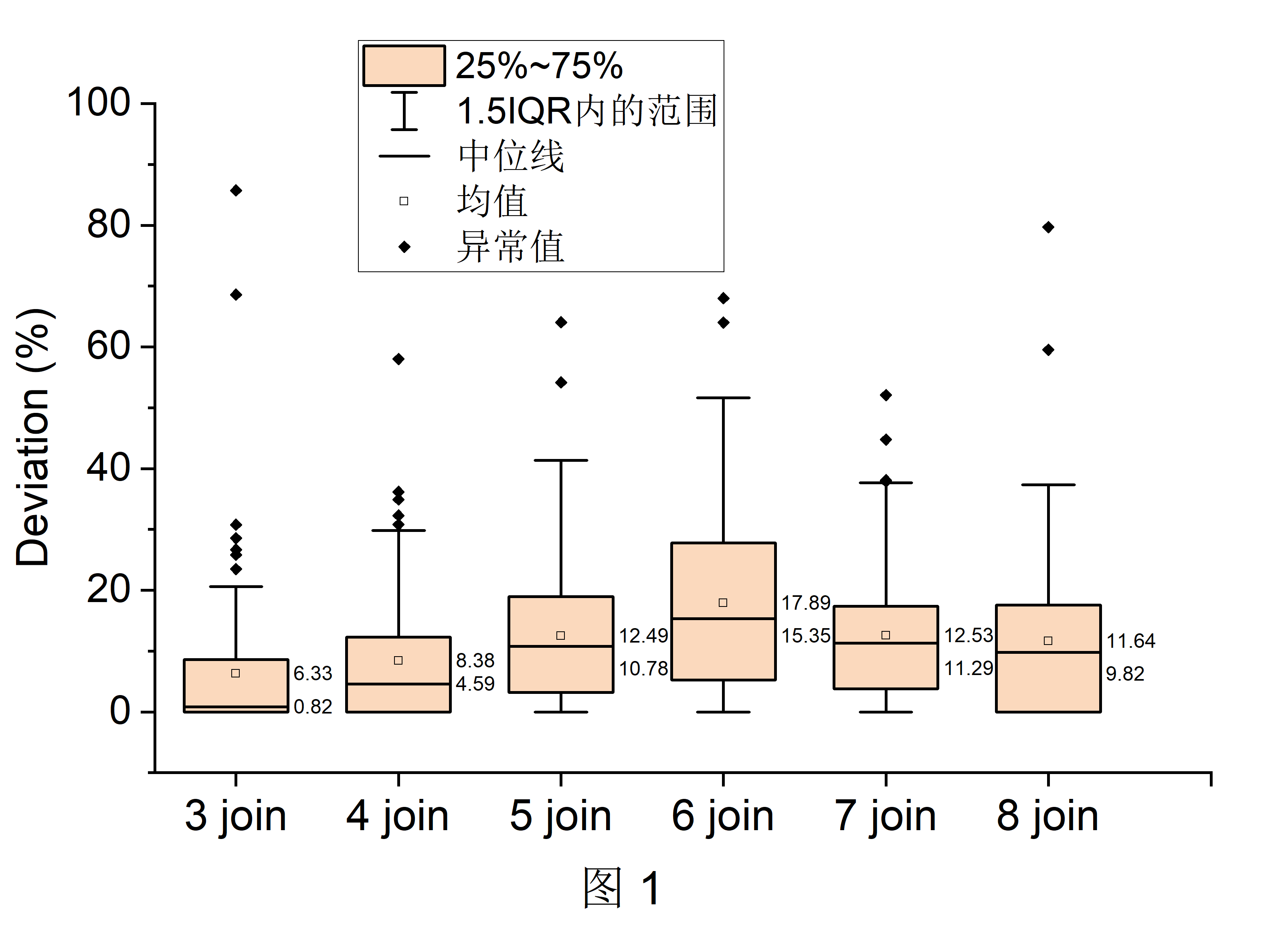
图1 展示了3~8张表连接时的deviation结果,横坐标表示参与连接表的数量,纵坐标表示优化器选择的连接顺序的执行时间与最优执行时间的偏差。
-
从图1中可以看到,当参与连接表的数量小于等于5时,偏差大部分低于20%。经过计算,我们得到去除异常值后,平均执行时间差低于42毫秒(执行时间差 = OceanBase选择的连接顺序执行时间 - 最优连接顺序执行时间)。
-
我们可以观察到,参与连接的表数目从3增长到6时,MRR值逐渐减少,deviation整体呈现增长趋势,如中位线从0.82%增长到15.35%(增长了17.7倍),均值从6.33%增长到17.89%(增长了1.8倍)。这个结果说明了随着参与连接的表数量增大,OceanBase选择的连接顺序在搜索空间中的排名越来越低,与最优连接顺序的执行时间偏差越来越大,优化器从连接顺序搜索空间中选择出最优连接顺序的性能下降了。
-
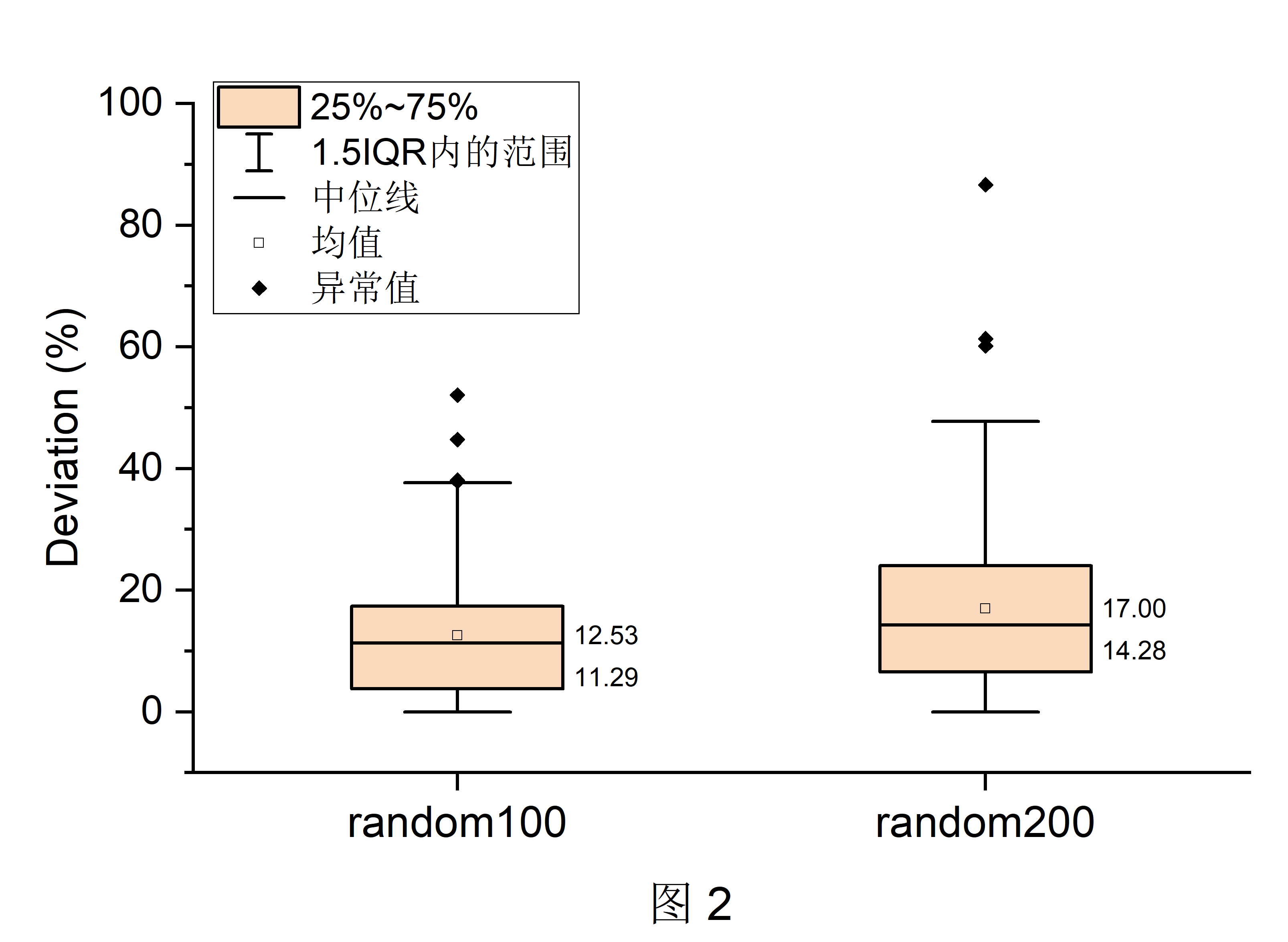
当表数量增加到7时,MRR值逐渐增大,deviation整体呈现下降趋势,这是因为我们仅仅从庞大的搜索空间中随机选择100个连接顺序进行评估,如7张表时仅选择了2% (100/5040)的连接顺序,8张表时仅选择了0.25% (100/40320)的连接顺序。我们很有可能并没有随机到最优的连接顺序。为此,我们增加了图2 的实验。
-
图2 展示了7张表参与连接时,分别随机选择100个连接顺序(random100)与随机选择200个连接顺序(random200)的deviation结果对比。我们可以看到,当随机的搜索空间增大时,deviation整体呈现增长趋势,中位线从11.29%增长到14.28%(增长了0.3倍),均值从12.53%增长到17.00%(增长了0.4倍)。同时,random200的MRR值为0.25,比random100的MRR值0.34下降了26.47%。这个结果说明了图1 的下降趋势与搜索空间的大小有关,即我们设定的搜索空间大小很大程度上影响了最终结果的准确性。
-
为了得到更精确的结果,更好的评估连接顺序选择,我们将在今后的实验中改进搜索空间的剪枝策略来代替随机选择。
5.2 案例分析
从图1中,我们可以看到有不少偏差较大的离散点,下面我们对其中两个点进行分析,探究偏差产生的原因。
5.2.1 案例一
-
图1 4张表参与连接时最大偏差为58.02%。
- 该点对应的查询为:
select count(*) as result from table_0, table_9, table_4, table_5 where table_4.col_8 <= 1922008581 and table_5.col_0 < -348809115.7006844609905468 and table_0.col_7 > -4255518.1398595209726152 and table_9.col_5 < -211145821.32382347996192376 and table_4.fk_3 = table_5.primaryKey and table_4.fk_11 = table_0.primaryKey and table_9.fk_2 = table_0.primaryKey; -
为了避免高偏差是由数据异常等原因导致的,我们重新执行该查询及其对应最优连接顺序:
分别执行7次,计算平均执行时间(去除最大最小值)。

两者偏差为30.43%,可见该查询的偏差依旧较大。 - EXPLAIN该查询得到执行计划如下:
| ======================================================
|ID|OPERATOR |NAME |EST. ROWS|COST |
------------------------------------------------------
|0 |SCALAR GROUP BY | |1 |923737|
|1 | HASH JOIN | |353299 |856253|
|2 | PX COORDINATOR | |7804 |19664 |
|3 | EXCHANGE OUT DISTR |:EX10000|7804 |18925 |
|4 | TABLE SCAN |table_9 |7804 |18925 |
|5 | HASH JOIN | |32468 |606413|
|6 | PX COORDINATOR | |710 |1777 |
|7 | EXCHANGE OUT DISTR |:EX20000|710 |1710 |
|8 | TABLE SCAN |table_0 |710 |1710 |
|9 | HASH JOIN | |32796 |573707|
|10| TABLE SCAN |table_4 |33127 |274978|
|11| PX COORDINATOR | |82996 |203567|
|12| EXCHANGE OUT DISTR|:EX30000|82996 |195711|
|13| TABLE SCAN |table_5 |82996 |195711|
======================================================
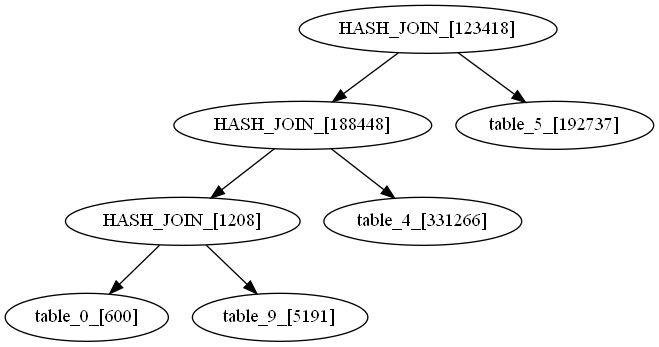
- OceanBase优化器选择的连接顺序为
((table_4⋈table_5)⋈table_0)⋈table_9,实验得到最优的连接顺序为((table_0⋈table_9)⋈table_4)⋈table_5。 -
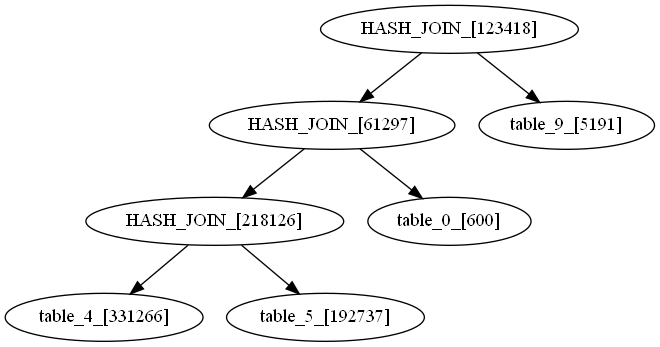
我们画出两个连接顺序的查询树如下(上面为OceanBase选择的连接顺序,下面为最优连接顺序):
-
节点中”[]”内的数字是操作的真实基数(中间结果大小),其中join操作的基数是两表连接后的中间结果大小,scan操作的基数是表经过条件过滤后的中间结果大小。
-
- 我们可以看出,最优连接顺序的join操作的基数更小,或许是优化器对基数的错误估计误导了连接顺序的选择。
5.2.2 案例二
-
从图1中,我们可以看到偏差最大的是3 join中的一点 (85.73%)。
-
该点查询为:
select count(*) as result from table_2, table_14, table_10
where table_2.col_4 < 1702600163 and table_14.col_1 <= 39586856.6599801245771715
and table_10.col_8 > -633452491.72604654429895750
and table_2.fk_0 = table_14.primaryKey
and table_10.fk_0 = table_14.primaryKey;
- OceanBase优化器选择的连接顺序为
(table_14⋈table_2)⋈table_10,实验得到最优的连接顺序为(table_2⋈table_14)⋈table_10。 -
为了避免高偏差是由数据异常等原因导致的,我们重新执行该query及其对应最优连接顺序:
分别执行7次,计算平均执行时间(去除最大最小值)。

两者偏差为64.85%,可见该query的偏差的确较大。 - EXPLAIN该查询得到执行计划如下:
obclient> EXPLAIN select count(*) as result from table_2, table_14, table_10
where table_2.col_4 < 1702600163 and table_14.col_1 <= 39586856.6599801245771715
and table_10.col_8 > -633452491.72604654429895750
and table_2.fk_0 = table_14.primaryKey
and table_10.fk_0 = table_14.primaryKey;
| ======================================================
|ID|OPERATOR |NAME |EST. ROWS|COST |
------------------------------------------------------
|0 |SCALAR GROUP BY | |1 |12360781|
|1 | HASH JOIN | |14725630 |9548003 |
|2 | PX COORDINATOR | |44555 |414608 |
|3 | EXCHANGE OUT DISTR|:EX10000|44555 |406173 |
|4 | HASH JOIN | |44555 |406173 |
|5 | TABLE SCAN |table_14|356 |874 |
|6 | TABLE SCAN |table_2 |45005 |363648 |
|7 | TABLE SCAN |table_10|118626 |287577 |
======================================================
- EXPLAIN最优连接顺序得到执行计划如下:
obclient> EXPLAIN select /*+LEADING(table_2, table_14, table_10)*/ count(*) as result from table_2, table_14, table_10
where table_2.col_4 < 1702600163 and table_14.col_1 <= 39586856.6599801245771715
and table_10.col_8 > -633452491.72604654429895750
and table_2.fk_0 = table_14.primaryKey
and table_10.fk_0 = table_14.primaryKey;
| ======================================================
|ID|OPERATOR |NAME |EST. ROWS|COST |
------------------------------------------------------
|0 |SCALAR GROUP BY | |1 |12360781|
|1 | HASH JOIN | |14725630 |9548003 |
|2 | PX COORDINATOR | |44555 |414608 |
|3 | EXCHANGE OUT DISTR|:EX10000|44555 |406173 |
|4 | HASH JOIN | |44555 |406173 |
|5 | TABLE SCAN |table_2 |45005 |363648 |
|6 | TABLE SCAN |table_14|356 |874 |
|7 | TABLE SCAN |table_10|118626 |287577 |
======================================================
-
其中,table_2经条件过滤后共450068行数据,table_14经条件过滤后共1066行数据。
-
这里我们发现一个有趣的现象,两个执行计划的区别在于table_2和table_14进行hash join时谁作为hash表,前者以table_14作为hash表,后者以table_2作为hash表。按理来说,小表作为hash表,然后去扫描另一张表的每一行数据,用得出来的行数据根据连接条件去映射建立的hash表。而这里table_14作为小表充当hash表的执行效率却不如table_2充当hash表。后续的hash join算子优化或许可以将这个现象考虑进去。
六、总结
经过上述实验,我们将OceanBase在连接顺序选择上的表现作以下总结:
- 当参与连接的表数量小于等于5时,OceanBase的表现还是不错的,执行时间与最优的偏差大部分低于20%,平均执行时间差低于42毫秒。
- 随着参与连接的表数量增长,OceanBase选择的连接顺序在搜索空间中的排名逐渐降低,与最优连接顺序的执行时间偏差逐渐增大,优化器从搜索空间中选择出最优连接顺序的性能呈现下降趋势。可以看出多表连接的优化还是一个难点问题。