OceanBase内核初探

💡 作者:华东师范大学 数据科学与工程学院 DBHammer项目组 东亚男儿团队
本文主体面向对OceanBase数据库源码以及系统性能优化感兴趣的初学者供以技术交流,笔者来自华东师范大学数据科学与工程学院DBHammer项目组。
本文主体分为三个部分:如何快速对OceanBase进行调试;系统性能优化利器-火焰图的简要介绍;面向赛题Nested Loop Join的应用场景,如何进行性能优化。
OceanBase快速Debug
引言
本文以在VSCode编辑器上OceanBase 3.1版本为例,进行Debug的教学,本地OB搭建的教程可以参考使用源码构建 OceanBase 数据库 和 使用OBD部署OceanBase。需要注意的是OBD目前只有rpm包,在Ubuntu环境下的具体安装方法可见Install RPM packages on Ubuntu | Linuxize。
步骤一:创建租户
在安装部署好OB后,接下来我们需要创建一个租户。当OB集群创建完成时,只有一个默认的sys租户,而sys租户仅用于集群管理,并不能支持测试服务,因此我们需要手动创建新的租户用于测试。
OBD提供了方便的创建租户的命令。 在OB比赛的简单场景中,我们仅创建一个租户:
obd cluster tenant create obadvanced --tenant-name mysql
这个命令创建了一个名为mysql 的租户,并为它分配了剩下的所有系统资源,没有设置密码。
接着我们使用mysql租户连接数据库,加上-c以确保之后输入的sql hint生效:
mysql -uroot@mysql -h127.0.0.1 -P 2881 -c
输入指令后即可看到数据库连接界面:
步骤二:配置launch.json
假定大家现在已经搭建了一款本地的OB且创建好了相应的租户,那么接下来我们需要在.vscode目录下创建launch.json文件以配置具体的gdb调试环境。
我们采取的是gdb attach
以下我们给出一个示例文件:
(其中出现的一些诸如ob-advanced这种创建OB时自定义的名称或者文件目录位置都需要再自行调整,sourceFileMap也可能需要根据需求手动增加mapping,更多的json配置项语义可见官网)
{
"configurations": [
{
"name": "(gdb) Attach",
"type": "cppdbg",
"request": "attach",
"program": "/data/ob-advanced/bin/observer",
"processId": "${input:FindPID}",
"MIMode": "gdb",
"sudo": true,
"miDebuggerPath": "gdb",
"setupCommands": [
{
"description": "Enable pretty-printing for gdb",
"text": "-enable-pretty-printing",
"ignoreFailures": true
}
],
"sourceFileMap": {
"./build_debug/src/observer/./src/observer/omt": {
"editorPath": "${workspaceFolder}/src/observer/omt"
},
"./build_debug/src/sql/parser/./src/sql/parser": {
"editorPath": "${workspaceFolder}/src/sql/parser",
"useForBreakpoints": true
},
"./build_debug/src/sql/./src/sql": {
"editorPath": "${workspaceFolder}/src/sql",
"useForBreakpoints": true
},
"./build_debug/src/storage/./src/storage": {
"editorPath": "${workspaceFolder}/src/storage",
"useForBreakpoints": true
},
"./build_debug/src/sql/engine/join/./src/sql/engine/join": {
"editorPath": "${workspaceFolder}/src/sql/engine/join",
"useForBreakpoints": true
}
}
}
],
"inputs": [
{
"id": "FindPID",
"type": "command",
"command": "shellCommand.execute",
"args": {
"command": "ps -aux | grep /bin/observer | grep -v \\"grep\\" | awk '{print $2}'",
"description": "Select your observer PID",
"useFirstResult": true,
}
}
]
}
💡 如果遇到下面的问题
Authentication is needed to run/usr/bin/gdb’ as the super user` 可以输入指令echo 0| sudo tee /proc/sys/kernel/yama/ptrace_scope调整权限解决
最终点击左上角的调试按钮,等待一段时间后,即可看到完整的调试界面,如下图所示:

步骤三:增加Breakpoint和所需观测变量
接着我们通过obclient/mysql模式连接OB。
为了调试的方便,我们可能需要适当增大事务超时时间以避免调试内部因可能的超时原因提前终止而影响判断。
set global ob_trx_idle_timeout=120000000;
set global ob_trx_timeout=36000000000;
set global ob_query_timeout=3600000000
比如,我们想先观察一下当前的场景是否开启了batch操作,即可在ob_nested_loop_join_op.cpp:read_left_operate函数里打上断点(也可以右键编辑条件断点)。
接着我们在命令行中输入负载样例:
select /*+ordered use_nl(A,B)*/ * from t1 A, t2 B where A.c1 >= -100 and A.c1 < 200 and A.c2 = B.c2;
等待片刻即可看到如下所示的debug界面:具体有四大信息栏值得关注:
- 工具栏:继续执行到下一个breakpoint、单步跳过、单步跳出、单步调试等基本调试操作;
- 变量栏:在此可以展开变量,观察程序执行期间各变量具体的值信息;
- 堆栈信息栏:在此可以观测到当前程序执行期间堆栈的上下文调用信息,便以快速把握代码的整体调用结构;
- 监视栏:由于变量栏里的很多变量都是指针,我们对其进行观测时只能看到变量的地址信息。那么我们在监视栏一方面可以执行基本的类型转换,取出指针指向的具体值信息,另一方面也可以一直保留某些需要持续观测的变量。

以上便是对OceanBase的debug调试方法的全部介绍。
除了通过debug从执行的细节上见微知著,我们还可以通过火焰图对程序的整体执行有一个宏观的把握,在此我们简单介绍一下火焰图的使用方法,希望对大家有所帮助。
火焰图介绍
什么是火焰图
火焰图由性能优化大师Brendan Gregg发明,以图像的形式形象地展示了程序执行时的调用堆栈信息,从底向上展示函数的执行比例,便于技术人员从中把握可能的性能瓶颈。因其颜色以红黄橙等暖色为主,像是跳动的火焰,故称Flame Graph,下图为OceanBase v3.1的整体火焰图。
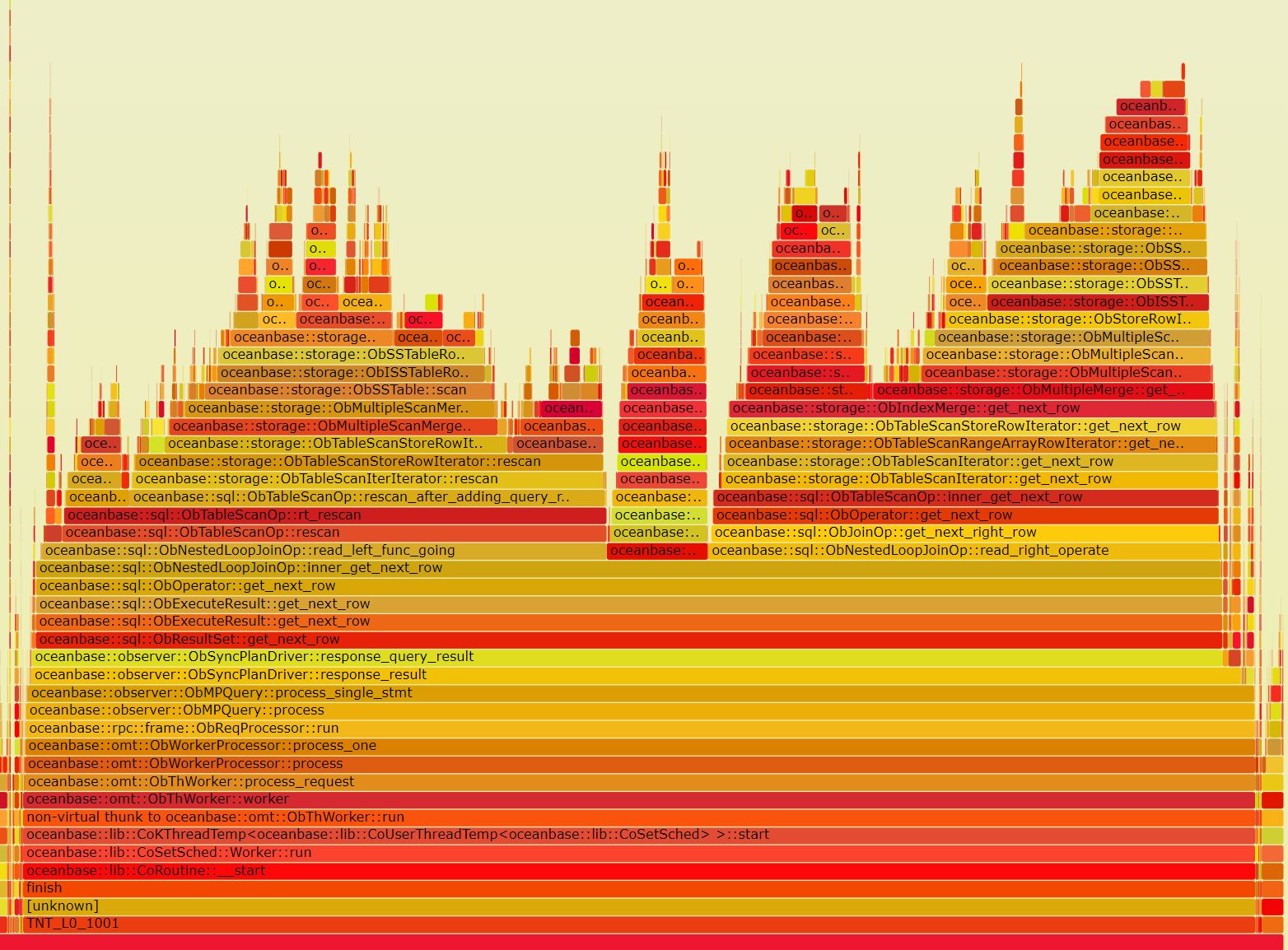
悬浮其上便能看到某个函数具体的执行比例:

关于火焰图相关的介绍文档和视频有很多,我们在此就不再赘述了,仅在下面作一个简要的概括,更详细的介绍可参见文章底部提供的链接。
火焰图主体有以下特征(这里以 on-cpu 火焰图为例):
- 每一列代表一个调用栈,每一个格子代表一个函数(一个栈帧)
- Y轴展示了栈的深度,按照调用关系从下到上排列。最顶上的格子代表当执行采样收集时,当前正在占用 cpu 的函数。每个格子下面的格子即是它的父函数。
- X轴展示了火焰图将要采集的不同调用栈信息,从左到右以函数名称的字母序顺序排列,但需要注意的是,横向的排序并不代表时间的流逝,其本身排序是没有任何实义的。
- 横轴格子的宽度代表其在采样中出现频率,其宽度与实际在堆栈中执行的时间长成正比,因此如果一个格子的宽度越大,说明它是瓶颈原因的可能性就越大。
- 火焰图格子的颜色是随机的暖色调,其颜色深浅并无具体实义,只是单纯为了方便区分各个调用信息。

以Brendan Gregg所给示意图来说:
- 顶端的格子显示函数g()占用CPU的时间最多;
- 函数d()更宽,但其暴露的顶端边缘在CPU上运行得最少(相较于e、f来说),说明我们可能更需要关注其子函数的调用;
- b()和c()两个函数似乎并没有直接在CPU上采样,实际在CPU上执行的函数都是它们的子函数;
- g()下面的函数显示了它的祖先:g()被f()调用,而f()又被d()调用,以此类推;
- 从视觉上比较函数b()和h()的宽度可以看出,b()的代码路径在CPU上的时间占用上是h()的4倍;
- 在a()调用b()和h()的地方,可以看到代码路径中存在一个分叉,这可能是一个条件判断的结果(即如果有条件,就调用b(),否则就调用h())或者是一个程序执行逻辑上的阶段分组(a()被分成两部分处理:b()和h())。
- 需要注意的是,OB内部存在协程,因此,一个格子暴露的边缘部分并不一定就是其运行的时间,这一点可能需要通过看汇编代码来确定。
如何获取火焰图
火焰图本身的制作是基于perf生成的data数据进行的,下面我们便进入工具的使用介绍:
- 获取Flame Graph工具:
git clone [<https://github.com/brendangregg/FlameGraph.git>](<https://github.com/brendangregg/FlameGraph.git>) - 执行perf record -F 99 -g -p 127 – sleep 20,在当前目录下生成采样数据perf.data.
- 意即基于某个指定pid,以99hz频率采样,持续10s
- 更多的指令详见https://www.brendangregg.com/perf.html
- 执行
perf script -i perf.data &> perf.unfold,用perf script工具读取perf.data结果,并对perf.data进行解析,其输出格式如下:
/read_left_operate
ffffffffb86dc289 finish_task_switch+0x199 ([kernel.kallsyms])
ffffffffb9200a46 __sched_text_start+0x2f6 ([kernel.kallsyms])
ffffffffb920109f schedule+0x4f ([kernel.kallsyms])
ffffffffb873bfd3 exit_to_user_mode_prepare+0xf3 ([kernel.kallsyms])
ffffffffb91f7be9 irqentry_exit_to_user_mode+0x9 ([kernel.kallsyms])
ffffffffb91f7c19 irqentry_exit+0x19 ([kernel.kallsyms])
ffffffffb91f6c7e sysvec_reschedule_ipi+0x7e ([kernel.kallsyms])
ffffffffb9400dc2 asm_sysvec_reschedule_ipi+0x12 ([kernel.kallsyms])
972e9a0 oceanbase::storage::ObQueryIteratorConsumer::set_consumer_num+0x0 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
9617ac1 oceanbase::storage::ObMultipleScanMergeImpl::inner_get_next_row+0xb1 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
961793e oceanbase::storage::ObMultipleScanMerge::inner_get_next_row+0x2e (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
9609eff oceanbase::storage::ObMultipleMerge::get_next_row+0x44f (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
9aa2c49 oceanbase::storage::ObTableScanStoreRowIterator::get_next_row+0x119 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
9aa3807 oceanbase::storage::ObTableScanRangeArrayRowIterator::get_next_row+0x117 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
9aa4bb7 oceanbase::storage::ObTableScanIterator::get_next_row+0x1d7 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
9b42a55 oceanbase::storage::ObTableScanIterator::get_next_row+0x25 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
48266b7 oceanbase::sql::ObTableScanOp::get_next_row_with_mode+0x97 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
4826aa8 oceanbase::sql::ObTableScanOp::inner_get_next_row+0x3d8 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
56aa469 oceanbase::sql::ObOperator::get_next_row+0x189 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
38731eb oceanbase::sql::ObJoinOp::get_next_left_row+0x2b (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
38752d3 oceanbase::sql::ObBasicNestedLoopJoinOp::get_next_left_row+0x1a3 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
3879c31 oceanbase::sql::ObNestedLoopJoinOp::group_read_left_operate+0xb71 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
3876cf9 oceanbase::sql::ObNestedLoopJoinOp::read_left_operate+0x39 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
38782a2 oceanbase::sql::ObNestedLoopJoinOp::inner_get_next_row+0x262 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
56aa469 oceanbase::sql::ObOperator::get_next_row+0x189 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
4cee252 oceanbase::sql::ObExecuteResult::get_next_row+0x152 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
4ced5c7 oceanbase::sql::ObExecuteResult::get_next_row+0x47 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
64084ee oceanbase::sql::ObResultSet::get_next_row+0x13e (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
a3c0b01 oceanbase::observer::ObSyncPlanDriver::response_query_result+0x3d1 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
a3bf493 oceanbase::observer::ObSyncPlanDriver::response_result+0x4b3 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
a3f5d09 oceanbase::observer::ObMPQuery::process_single_stmt+0x3669 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
a3f135d oceanbase::observer::ObMPQuery::process+0x222d (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
b3d20bd oceanbase::rpc::frame::ObReqProcessor::run+0x3ed (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
a750cb0 oceanbase::omt::ObWorkerProcessor::process_one+0x240 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
a72e41a oceanbase::omt::ObWorkerProcessor::process+0x8ea (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
a74ea86 oceanbase::omt::ObThWorker::process_request+0x3e6 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
a72c33d oceanbase::omt::ObThWorker::worker+0x10cd (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
a72c80c oceanbase::omt::ObThWorker::run+0x3c (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
2af48ec oceanbase::lib::CoKThreadTemp<oceanbase::lib::CoUserThreadTemp<oceanbase::lib::CoSetSched> >::start()::{lambda()#1}::operator()+0x4c (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
2af477d std::_Function_handler<void (), oceanbase::lib::CoKThreadTemp<oceanbase::lib::CoUserThreadTemp<oceanbase::lib::CoSetSched> >::start()::{lambda()#1}>::_M_invoke+0x1d (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
1e4f14e std::function<void ()>::operator()+0x3e (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
af877b5 oceanbase::lib::CoSetSched::Worker::run+0x45 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
af86155 oceanbase::lib::CoRoutine::__start+0x1b5 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
af7eeaf finish+0x0 (/data/ob-advanced/bin/observer.another-commit-915609a0-25_20:01:00-debug)
ccccccccccccccf4 [unknown] ([unknown])
- 执行
FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded,接着将perf.unfold中的符号进行折叠,组织成火焰图所需的统一格式 - 执行
FlameGraph/flamegraph.pl perf.folded > perf.svg,最后生成svg格式的火焰图
以下是一个样例脚本供自动化生成OceanBase的Flame Graph,感谢复赛的lhcmaple队伍提供了这个脚本,我们稍作了一些改进。
#!/bin/bash
# no parameter is needed, just run
PID=$(ps -aux | grep /bin/observer | grep -v \"grep\" | awk '{print $2}')
if [ ${#PID} -eq 0 ]
then
echo "observer is not running"
exit -1
fi
perf record -F 99 -g -p $PID -- sleep 20
perf script -i perf.data &> perf.unfold
FlameGraph/stackcollapse-perf.pl perf.unfold &> perf.folded
FlameGraph/flamegraph.pl perf.folded > perf.svg
当然,尽管火焰图的可视化对于性能优化debug的确大有裨益,但原生的perf操作对数据的统计信息和操控粒度会更加丰富和深入,二者互相配合,才能相得益彰。
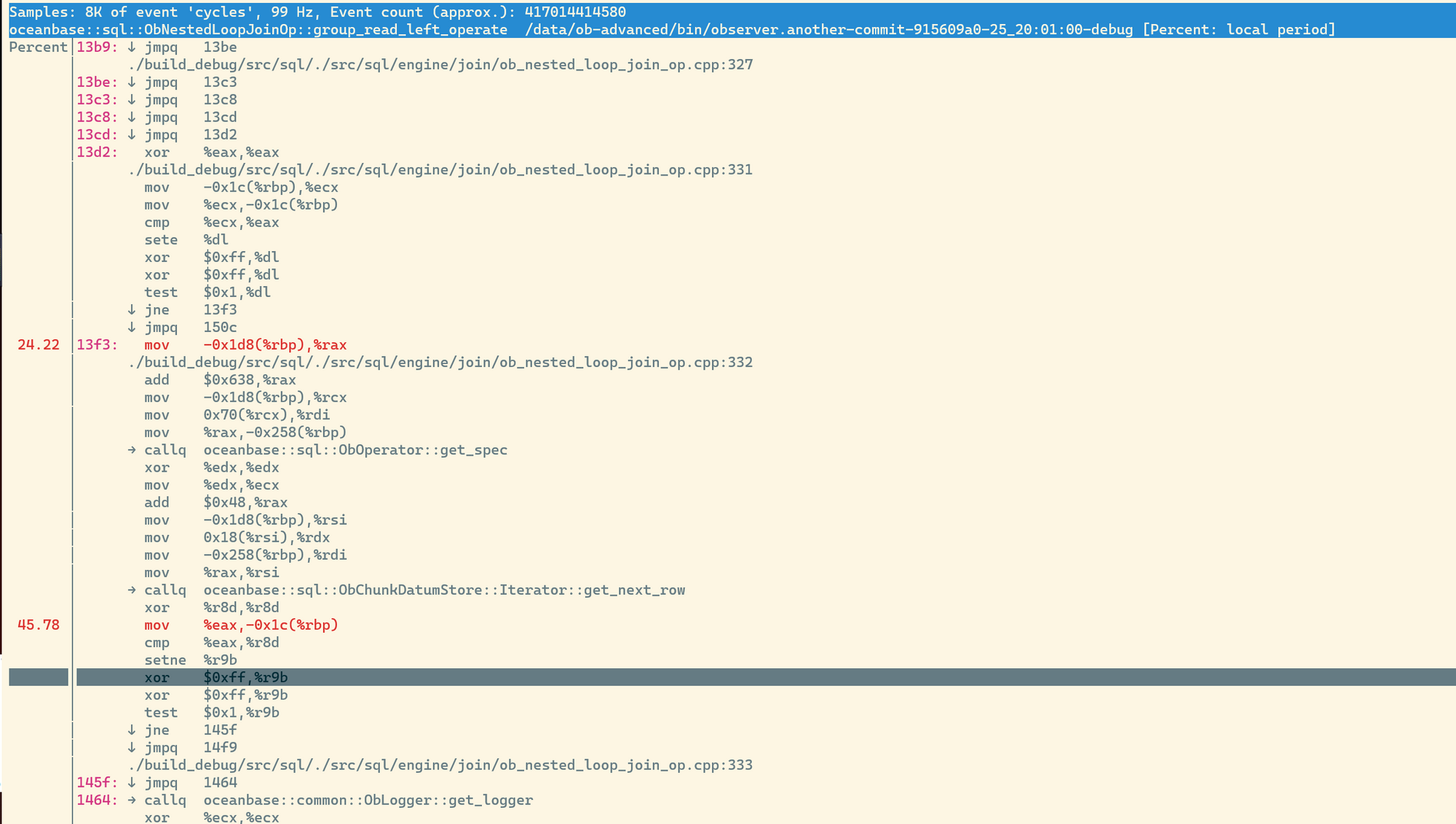
比如我们在步骤一统计完perf.data信息后,可以直接输入perf report查看命令行内的树状信息,如下图所示:
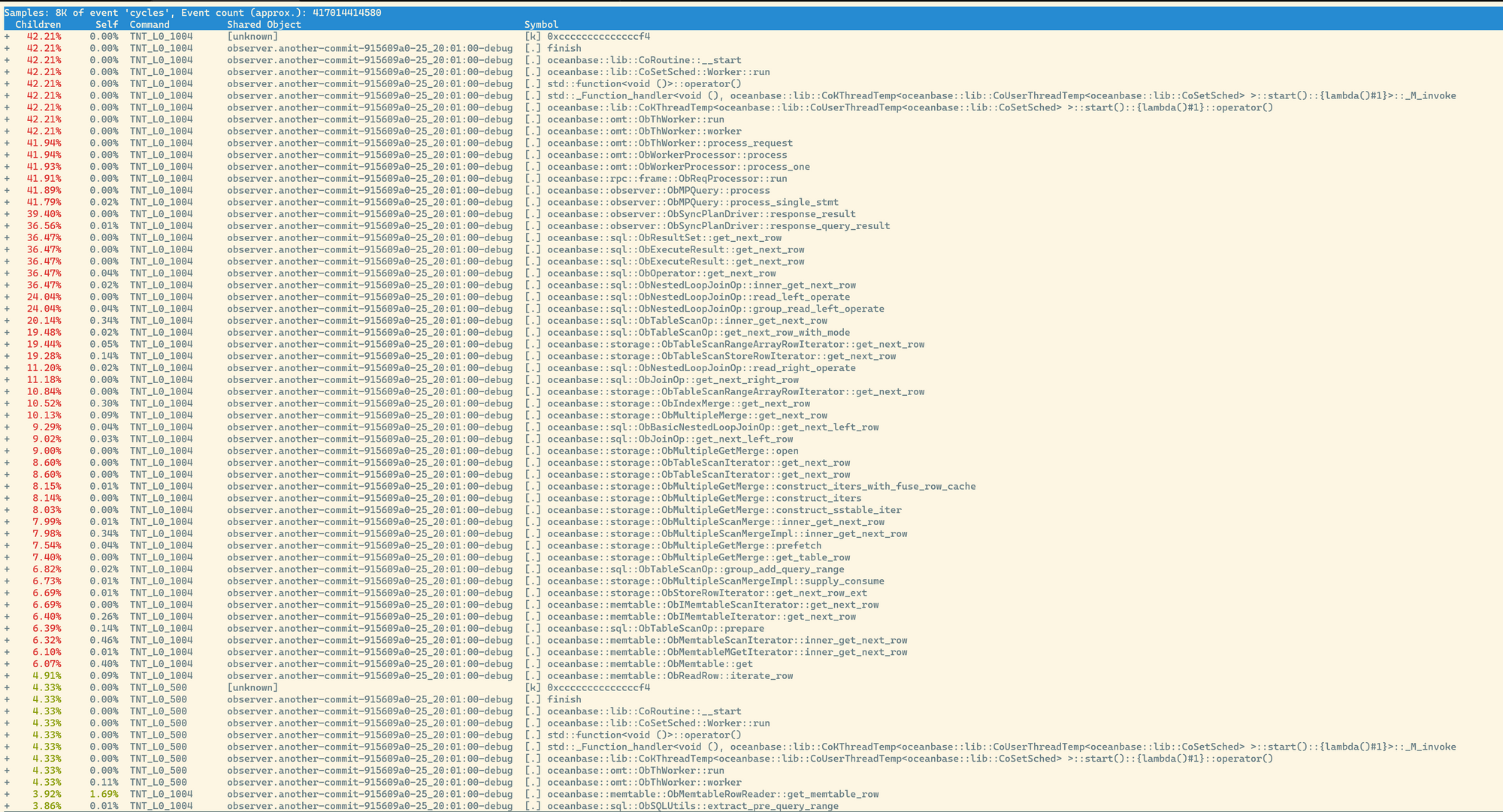
我们输入/group_read_left_operate快速搜索定位到我们所需要的函数:

接着按下a,即可展开具体的堆栈信息,且以汇编的形式陈列,这便可以帮助我们确定某些优化是否真正起到了作用,比如循环展开(Loop Unrolling),可能我们需要通过汇编才能真正确定其是否优化到了我们预期的效果。
工欲善其事,必先利其器,有了如上如此方便快捷的调试方法和性能分析利器火焰图,接下来我们便需要开始着手思考赛题了。
性能优化方向
本次赛题是在开源 OceanBase 基础之上,针对 Nested Loop Join(NLJ) 场景做性能优化。
测试所使用的查询语句为select /*+ordered use_nl(A,B)*/ * from t1 A, t2 B where A.c1 >= ? and A.c1 < ? and A.c2 = B.c2 and A.c3 = B.c3;。
我们explain这条SQL语句,可得到如下结果:
可以看到,查询语句中包含两个join条件和一个对t1表的范围过滤,在过滤后,左表t1的数据量会显著小于右表t2。同时,t1.c2=t2.c2这一join条件会使用到t2.c2这一索引。
explain extended select /*+ordered use_nl(A,B)*/ * from t1 A, t2 B where A.c1 >= 56107 and A.c1 < 56307 and A.c2 = B.c2 and A.c3 = B.c3;
| ================================================
|ID|OPERATOR |NAME |EST. ROWS|COST |
------------------------------------------------
|0 |NESTED-LOOP JOIN| |2718 |1306675|
|1 | TABLE SCAN |A |200 |78 |
|2 | TABLE SCAN |B(t2_i1)|10 |6530 |
================================================
----
2 - is_index_back=true
----
背景
NLJ的基本原理是每次从左表获取一行,然后用这行数据和右表进行JOIN。
通常来说,最简单的想法就是直接把右表的全部数据扫描上来,再跟左表的这行数据进行JOIN的话,那么程序整体的复杂度就是:M(左表行数)*N(右表行数)。
但在大部分的实际场景,为了降低复杂度,右表获取数据可以选取其他两种方案:
- JOIN条件本身是右表的rowkey(主键),可以直接通过主键索引获取到右表行(假设是聚合索引);
- 右表上面有普通索引,JOIN条件可以命中索引,那么可以根据左表这行数据先去查右表的索引,获得到右表的rowkey(主键),再利用主键去查找右表(这个过程叫做回表),获取到完整的行;
由于本次大赛的题目中右表上存在索引,因此可以应用方式2。同时,我们也可以从上述EXPLAIN执行计划印证这一点:左表是t1,右表是t2,扫描右表走了索引t2_i1回表。
NLJ整体执行流程
具体来说,该场景的具体实现可以分为3个部分:左表scan、rescan和右表scan回表。
左表scan:在这个场景中就是对t1表,根据主键范围进行扫描,并逐行返回,该模块涉及到的函数调用关系为:
ObNestedLoopJoinOp.read_left_operate->ObJoinOp.get_next_left_row->ObOperator.get_next_row->
ObTableScanOp.inner_get_next_row->ObTableScanIterator.get_next_row->ObTableScanRangeArrayRowIterator.get_next_row->
//往下为存储层
ObTableScanStoreRowIterator.get_next_row->ObMultipleMerge.get_next_row->ObMultipleScanMerge.inner_get_next_row->...
ObStoreRowIterator.get_next_row_ext->...
rescan:rescan发生在左表的上一行针对右表已经完成了JOIN的情况,这个时候OB并不会直接关闭右表的扫描,而是通过rescan重置右表的扫描状态,之后在左表扫描下一行时可以直接开始右表的扫描,而不用重新打开。具体来说,该模块涉及到的函数调用关系为:
ObNestedLoopJoinOp.read_left_func_going->
ObTableScanOp.rescan->ObTableScanOp.rt_rescan->ObTableScanOp.rescan_after_adding_query_range->
//往下为存储层
ObTableScanIterIterator.rescan->ObTableScanStoreRowIterator.rescan->
...
右表scan回表:在这个场景中就是先通过B.c2列查询索引t2_i1,获取到rowkey后再查询t2的过程,该模块涉及到的函数调用关系为:
ObNestedLoopJoinOp.read_right_operate->ObJoinOp.get_next_right_row->ObOperator.get_next_row->
ObTableScanOp.inner_get_next_row->ObTableScanIterator.get_next_row->ObTableScanRangeArrayRowIterator.get_next_row->
//往下为存储层
ObTableScanStoreRowIterator.get_next_row->ObIndexMerge.get_next_row->
...
存储层查询流程
OB的存储是基于LSM-Tree实现的,具体内容可以参考OB开源官网文档 LSM Tree 架构,以及同一个章节下的其它内容。
存储层查询是在多个memtable、sstable上迭代、归并的过程,按单行返回给上层。
OB目前的实现是为每一个memtable/sstable对应分配一个iterator,多个memtable/sstable对应的iterators维护在ObMultipleMerge类中,由Merge类完成从每个iterator获取1行数据,然后再进行归并的任务。
同时,OB的sstable内部是按照宏块-微块-行三层存储粒度组成,在iterator内部会先根据查询range定位到微块,然后通过微块对应的ObMicroBlockRowScanner打开读行。
总结来说,NLJ查询涉及的到存储层结构可以分为3层,multiple merge层,store row iter层,micro scanner/getter层,其关联关系如下所示:
multiple merge
-- iters 维护多个memtable/sstable的iterator,查询可能涉及到多个memtable/sstable做归并
store row iter
-- 单个memtable/sstable对应的迭代器
micro scanner/getter
-- 微块迭代器
所以理论上对于同一个查询中,同一个memtable/sstable只需要1个iterator就可以了。尽管对NLJ rescan场景需要对右表进行多次遍历,但在理想情况下还是可以只用这1个iterator完成多次遍历,不过OB目前的版本并没有实现这一点。
同时,在sstable iterator内部实际读数据时,是通过预取(prefetch)的方式把IO和解析读到的行数据串联起来,从而避免不必要的IO,CPU也可以流水线执行,极大提升了效率。
而针对目前这个NLJ场景,从执行计划可以看出这个查询会对两张表进行table scan,对t1表使用普通的迭代,对t2表使用索引回表(OB的索引回表实现在ObIndexMerge中)。
其落实到查询层的调用链路和执行过程列举如下:
1. 创建iterator并开始第1次预取
ObTableScanStoreRowIterator.open_iter->ObMultipleScan(get)Merge.construct_iters->ObSSTable(ObMemtable).scan(get)-> //分配iterator
ObISSTableRowIterator.init->ObSSTableRowIterator.inner_open-> // 初始化iterator
ObSSTableRowIterator.prefetch //预取数据
2.1. 持续预取并读数据(非回表)
get_next_row->..
2.2. 回表读取数据
ObIndexMerge.get_next_row->ObMultipleMerge.get_next_row->ObMultipleScanMerge.inner_get_next_row->...
->ObMultipleMerge.get_next_row->ObMultipleGetMerge.inner_get_next_row->...
优化方向
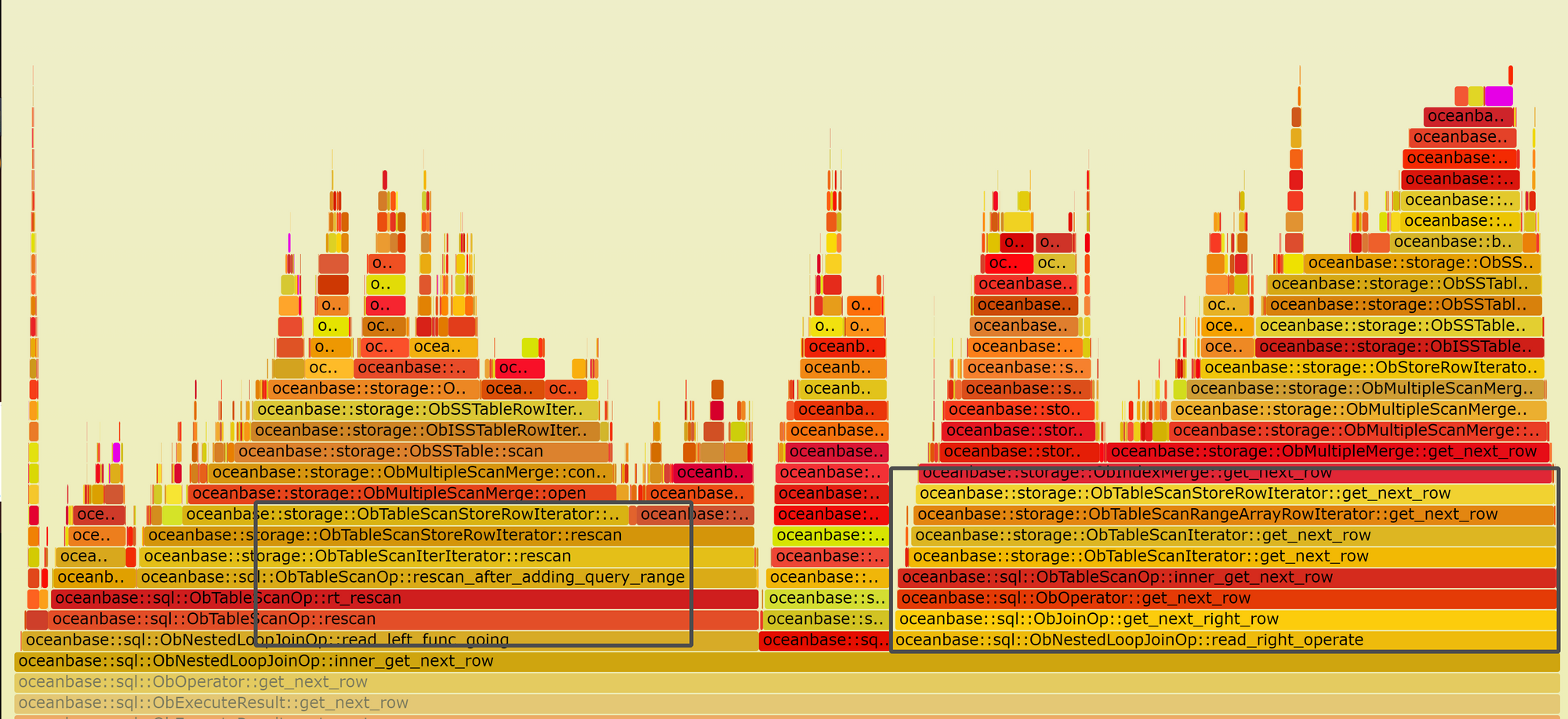
不难从OB的NLJ实现中和火焰图的占比上看出rescan和右表scan回表对性能影响比较大,我们以rescan为例分析当前的实现和可以改进的方向。
首先针对rescan,它的作用是使右表多次的扫描可以尽量复用对象,在如下代码中可以看到rescan释放和保留(重置)了哪些对象:
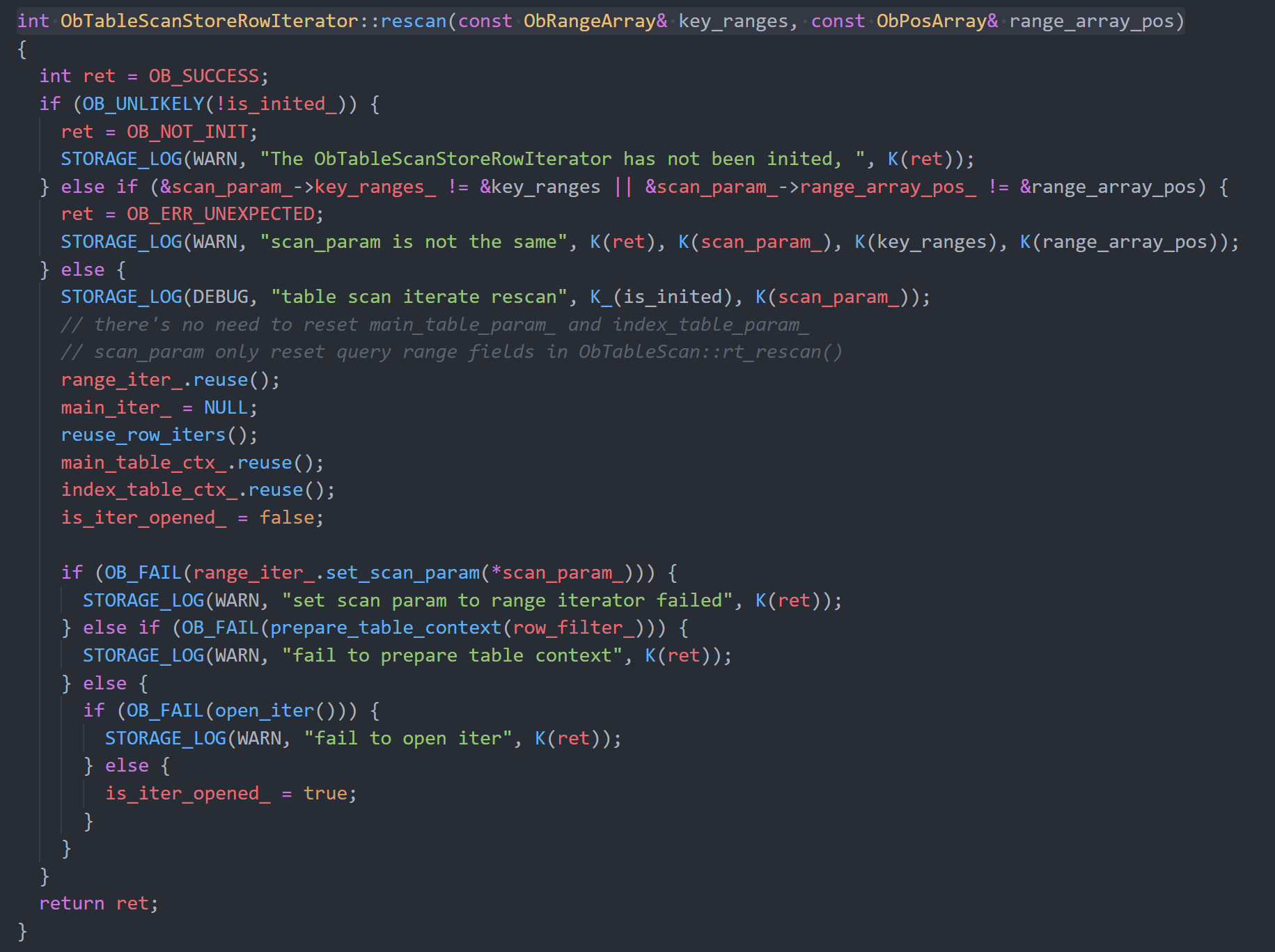
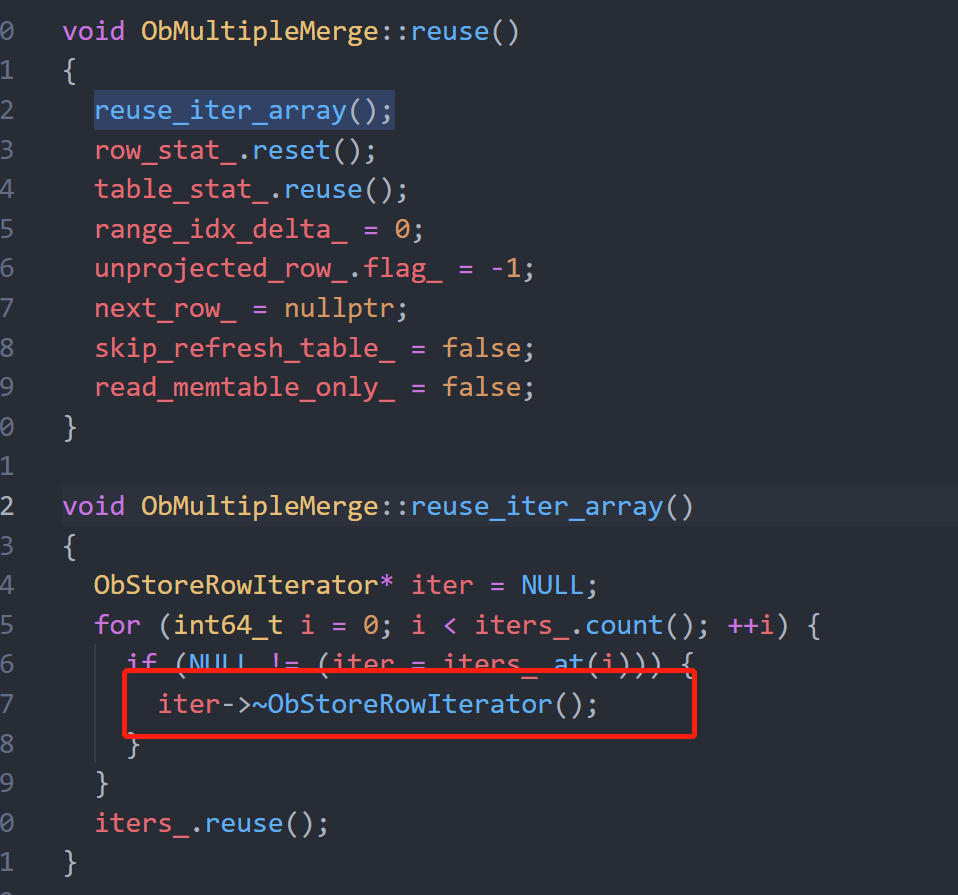
- rescan调用了reuse_row_iters,意图重用这个iter对象,但是在其内部实现,还是调用了~ObStoreRowIterator,经过继承关系(ObSSTableRowIterator→ObISSTableRowIterator→ObSSTableRowIterator)最终通过ObSSTableRowIterator析构掉了这个iter对象,并清空了iters数组,实际并没有起到复用的效果。
- 而现在的实现实际上是在open_iter中调用了construct_iters,接着再调用scan函数进行iter的初始化和重新分配,其调用栈信息如下火焰图所示:
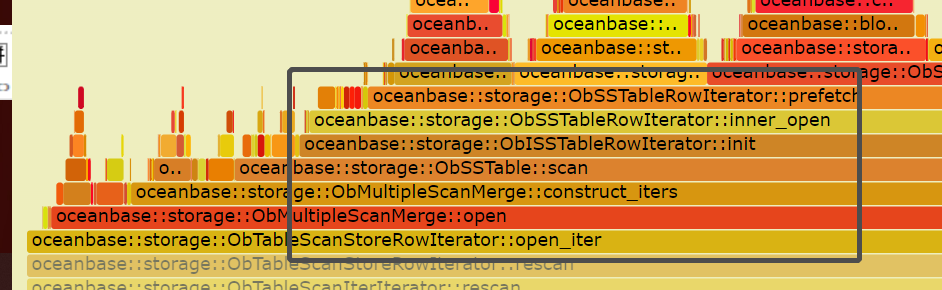
同时在scan函数中也会调用init进而通过inner_open函数进行实际的iter分配,最后设置row_iter的值。
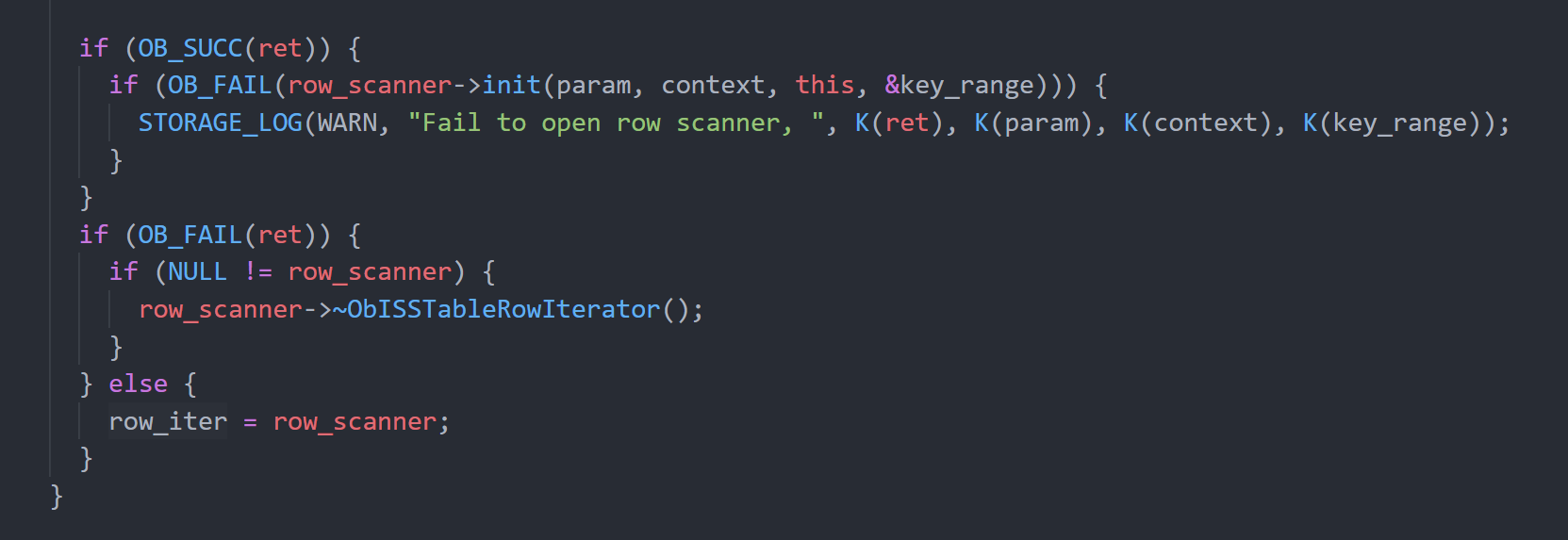
所以对于多次扫描实际使用的都是sstable iter对象,这里直接的改进方向是,rescan中不要析构掉和清理iters数组,然后保持iters在整个查询(多次rescan)一直有效。
为了实现这个目标,我们的大致思路如下:
首先我们需要内存保持有效,在最开始分配iter的地方使用适当的资源分配器(allocator)保证整个查询期间内存都不会被释放;接着当遇到析构的时候不再直接释放变量,而是调用iter的reuse接口,但同时也需要保留某些必须的清理动作,最大化复用迭代器,以实现性能的提升。
以上即是本文的全部内容了,希望能为各位同仁提供一些帮助和思路上的启发,如有疑问也可联系我们进行交流。