Oceanbase中LSM-Tree的分层设计及其优缺点

LSM Tree技术出现的一个最主要的原因就是磁盘的随机写速度要远远低于顺序写的速度,而数据库要面临很多写密集型的场景,所以很多数据库产品就把LSM Tree的思想引入到了数据库领域。LSM Tree ,顾名思义,就是The Log-Structured Merge-Tree 的缩写。从这个名称里面可以看到几个关键的信息:
第一:Log-Structred,通过日志的方式来组织的
第二:Merge,可以合并的
第三:Tree,一种树形结构
实际上它并不是一棵树,也不是一种具体的数据结构,它实际上是一种数据保存和更新的思想。简单的说,就是将数据按照key来进行排序(在数据库中就是表的主键),之后形成一棵一棵小的树形结构,或者不是树形结构,是一张小表也可以,这些数据通常被称为基线数据;之后把每次数据的改变(也就是log)都记录下来,也按照主键进行排序,之后定期的把log中对数据的改变合并(merge)到基线数据当中。下面的图形描述了LSM Tree的基本结构。
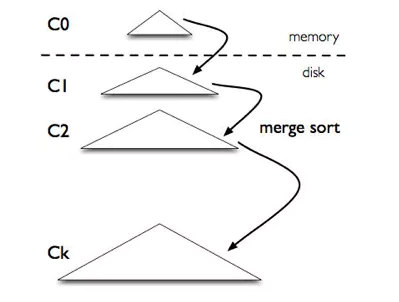
图中的C0代表了缓存在内存中的数据,当内存中的数据达到了一定的阈值后,就会把数据内存中的数据排序后保存到磁盘当中,这就形成了磁盘中C1级别的增量数据(这些数据也是按照主键排序的),这个过程通常被称为转储。当C1级别的数据也达到一定阈值的时候,就会触发另外的一次合并(合并的过程可以认为是一种归并排序的过程),形成C2级别的数据,以此类推,如果这个逐级合并的结构定义了k层的话,那么最后的第k层数据就是最后的基线数据,这个过程通常被称为合并。
用一句话来简单描述的话,LSM Tree就是一个基于归并排序的数据存储思想。从上面的结构中不难看出,LSM Tree对写密集型的应用是非常友好的,因为绝大部分的写操作都是顺序的。但是对很多读操作是要损失一些性能的,因为数据在磁盘上可能存在多个版本,所以通常情况下,使用了LSM Tree的存储引擎都会选择把很多个版本的数据存在内存中,根据查询的需要,构建出满足要求的数据版本。
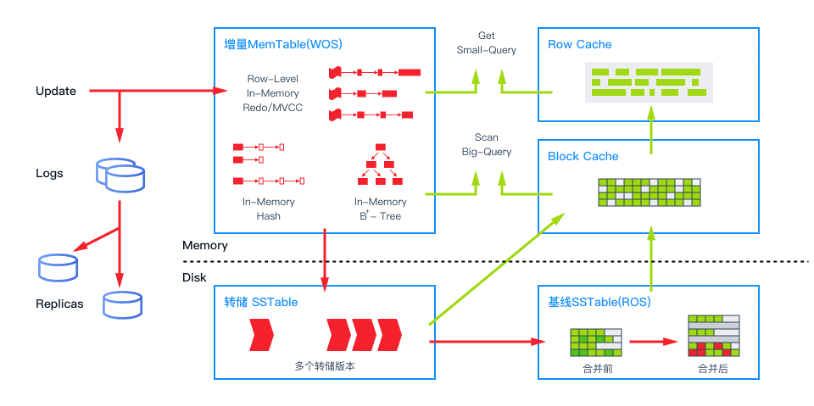
OceanBase 数据库的存储引擎基于 LSM Tree 架构,将数据分为静态基线数据(放在 SSTable 中)和动态增量数据(放在 MemTable 中)两部分,其中 SSTable 是只读的,一旦生成就不再被修改,存储于磁盘;MemTable 支持读写,存储于内存。数据库 DML 操作插入、更新、删除等首先写入 MemTable,等到 MemTable 达到一定大小时转储到磁盘成为 SSTable。在进行查询时,需要分别对 SSTable 和 MemTable 进行查询,并将查询结果进行归并,返回给 SQL 层归并后的查询结果。同时在内存实现了 Block Cache 和 Row cache,来避免对基线数据的随机读。
当内存的增量数据达到一定规模的时候,会触发增量数据和基线数据的合并,把增量数据落盘。同时每天晚上的空闲时刻,系统也会自动每日合并。
OceanBase 本质上是一个基线加增量的存储引擎,跟关系数据库差别很大,同时也借鉴了部分传统关系数据库存储引擎的优点。
传统数据库把数据分成很多页面,OceanBase 数据库也借鉴了传统数据库的思想,把数据分成很多 2MB 为单位的宏块。合并时采用增量合并的方式,OceanBase 数据库的合并代价相比 LevelDB 和 RocksDB 都会低很多。另外,OceanBase 数据库通过轮转合并的机制把正常服务和合并时间错开,使得合并操作对正常用户请求完全没有干扰。
由于 OceanBase 数据库采用基线加增量的设计,一部分数据在基线,一部分在增量,原理上每次查询都是既要读基线,也要读增量。为此,OceanBase 数据库做了很多的优化,尤其是针对单行的优化。OceanBase 数据库内部除了对数据块进行缓存之外,也会对行进行缓存,行缓存会极大加速对单行的查询性能。对于不存在行的“空查”,OceanBase 会构建布隆过滤器,并对布隆过滤器进行缓存。OLTP 业务大部分操作为小查询,通过小查询优化,OceanBase 数据库避免了传统数据库解析整个数据块的开销,达到了接近内存数据库的性能。另外,由于基线是只读数据,而且内部采用连续存储的方式,OceanBase 数据库可以采用比较激进的压缩算法,既能做到高压缩比,又不影响查询性能,大大降低了成本。