Polardb for PostgreSQL部署(Ceph+PFS)

简介
- 获取在同一网段的虚拟机三台,互相之间配置 ssh 免密登录,用作 ceph 密钥与配置信息的同步;
- 在主节点启动 mon 进程,查看状态,将其他主机添加到ceph集群中;
- 在三个环境中启动 osd 进程配置存储盘;
- 创建存储池与 rbd 块设备镜像,并对创建好的镜像在各个节点进行映射即可实现块设备的共享;
- 对块设备进行 PolarFS 的格式化
- 进行一个读写节点,两个只读节点的PolarDB 部署。
环境要求
系统盘25G,数据盘40G,image大小111G
内存大小>4G,CPU
ceph的部署需要:
1、Python3
2、Systemd【系统自带,不用安装】
3、运行容器的工具(Docker或Podman)
4、时间同步工具(NTP)
5、用于存储管理的工具(LVM2)【系统自带,不用安装】
一、配置Docker
1. 安装Dokcer
yum install -y yum-utils
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install -y docker-ce docker-ce-cli containerd.io docker-compose-plugin
2. 配置国内镜像
sudo mkdir /etc/docker
sudo vi /etc/docker/daemon.json
#输入以下内容
{
"registry-mirrors": ["https://registry.docker-cn.com"]
}
3. 启动Docker,并配置开机自启
systemctl start docker
systemctl enable docker
二、确定NTP服务启动
systemctl status ntpd
systemctl start ntpd #如果发现没有启动,则使用这个命令启动
三、配置Ceph
1. 配置环境
yum install -y python3
docker pull quay.io/ceph/ceph:v15
2. 下载Cephadm
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm
chmod +x cephadm
3. 安装Cephadm
./cephadm add-repo --release octopus
./cephadm install
cephadm install ceph-common
4. 启动Cephmon
任意选定一个节点作为ceph集群管理的主节点,通过ceph bootstrap在这个节点创建一个监控和管理的daemon进程,生成ceph集群的密钥文件/etc/ceph/ceph.pub、/etc/ceph/ceph.client.admin.keyring,以及集群的配置文件/etc/ceph/ceph.conf,跳过pull容器镜像quay.io/ceph/ceph:v15。
cephadm bootstrap --mon-ip $(hostname -I | cut -d ' ' -f1) --skip-pull #已在三.1拉取
四、添加主机节点
1. 配置主机间免密登录
在每台主机生成自己的公钥和私钥对
ssh-keygen
每台主机把自己的公钥发送给其他主机
ssh-copy-id -i .ssh/id_rsa.pub root@hostip
2. 添加当前主机到ceph集群中
ceph orch host add $(hostname) $(hostname -I | cut -d ' ' -f1)
4. 添加其他主机到ceph集群中
4.1 传输ceph集群的公钥给其他节点
把主节点的/etc/ceph/* 文件内的公私钥对和配置文件信息通过scp的方式传输给其他准备加入ceph集群的主机
mkdir /etc/ceph
scp /etc/ceph/* hostip:/etc/ceph/
4.2 添加其他主机到ceph集群中
# hostname为主机名,hostip为添加的主机ip,例如添加10.24.14.244的主机名为10-24-14-244
ceph orch host add hostname hostip
4.3 检查ceph集群状态
ceph -s
注意看quorum后面是否加入了3个主机
五、添加osd存储
ceph集群中的所有主机都要执行umount和osd添加
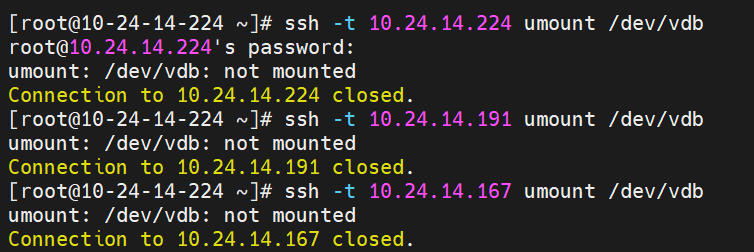
1. 卸载准备使用的磁盘块
ssh -t hostip umount /dev/vdb
2. 添加每个机器的空闲磁盘块为osd存储
ceph orch daemon add osd hostname:/dev/vdb

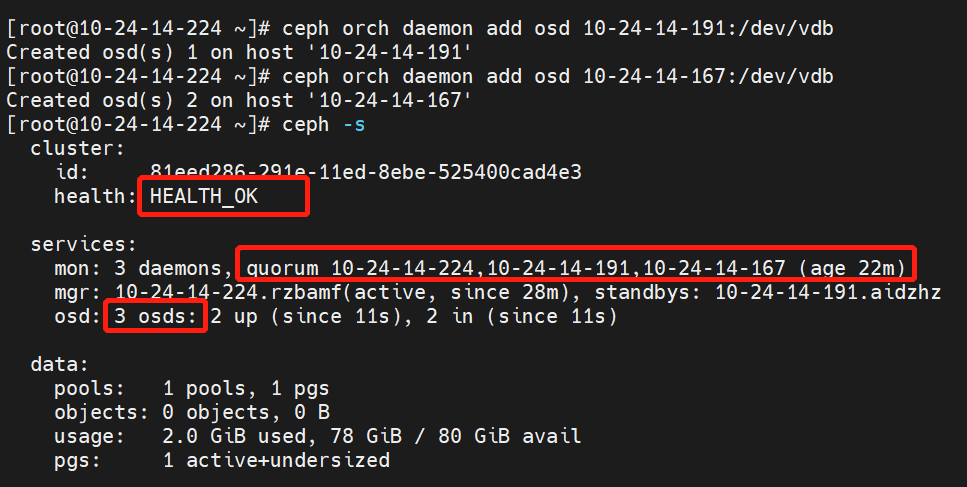
六、检查ceph集群状态
检查ceph集群状态是否为health_ok,同时看看是否所有的节点是否都加入了,osd启动的数量是否正确,可能会存在一定的延迟
ceph -s
七、创建osd pool并准备rbd块
存储池和镜像块的创建(1、2步)仅在主节点执行1次,(3、4步)映射镜像文件需要在所有节点执行
1. 创建存储池
ceph osd pool create rbd_polar
2. 创建镜像块
rbd create --size 113664 rbd_polar/image01 #小于单个/dev/vdb大小的3倍,这里使用的是111GB
ceph osd pool application enable rbd_polar rbd #启动osd pool application
rbd feature disable rbd_polar/image01 object-map fast-diff deep-flatten #关闭 rbd 不支持特性,才可以执行rbd map
3. 映射镜像文件
rbd map rbd_polar/image01
rbd device list #检查是否成功创建映射

4. 检查是否成功为主机存储识别
lsblk #检查是否成功出现rbd0

八、文件系统准备-配置PFS
1. PFS的编译安装
【定期更新】DockerHub 上的 PolarDB 开发镜像,其中已经包含了编译完毕的 PFS,无需再次编译安装,直接进入容器即可。
docker pull polardb/polardb_pg_devel
docker run -it \
--network=host \
--cap-add=SYS_PTRACE --privileged=true \
--name polardb_pg \
polardb/polardb_pg_devel bash

2.为块设备建立软连接
进入容器后执行,在所有的主机上执行(polarfs不能识别rb开头的磁盘,需要重映射)
sudo ln -s /dev/rbd0 /dev/vdc

3. 格式化块设备
选择任意一台主机,在共享存储块设备上格式化 PFS 分布式文件系统
sudo /usr/local/bin/pfs -C disk mkfs vdc
4. PFS文件系统挂载
在能够访问共享存储的所有主机节点上分别启动 PFS 守护进程并挂载 PFS 文件系统
sudo /usr/local/polarstore/pfsd/bin/start_pfsd.sh -p vdc

九、编译部署节点
1. 在所有节点编译polardb内核代码
从github拉取polardb的POLARDB_11_STABLE分支源代码(Gitee国内镜像)
git clone -b POLARDB_11_STABLE https://gitee.com/mirrors/PolarDB-for-PostgreSQL
进入源码目录,使用 --with-pfsd 选项编译 PolarDB 内核编译
cd PolarDB-for-PostgreSQL/
./polardb_build.sh --with-pfsd
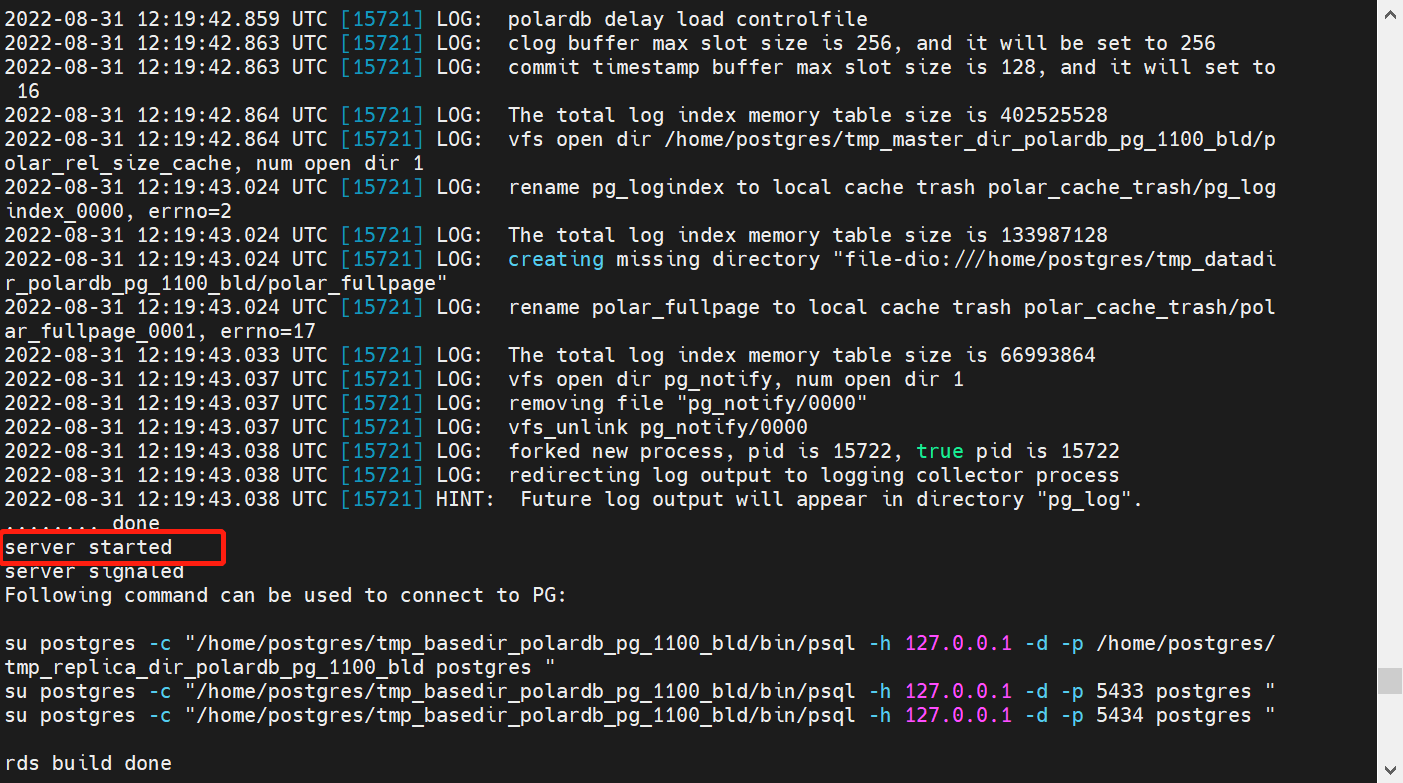 脚本在编译完成后,会自动部署一个基于本地文件系统的实例,运行于
脚本在编译完成后,会自动部署一个基于本地文件系统的实例,运行于 5432 端口上。手动键入以下命令停止这个实例,以便 在 PFS 和共享存储上重新部署实例
$HOME/tmp_basedir_polardb_pg_1100_bld/bin/pg_ctl \
-D $HOME/tmp_master_dir_polardb_pg_1100_bld/ \
stop
2. 配置读写节点(读写节点只有一个,建议选择主节点)
2.1 初始化数据目录$HOME/primary/
$HOME/tmp_basedir_polardb_pg_1100_bld/bin/initdb -D $HOME/primary

2.2 在共享存储的 /vdc/shared_data/ 目录上初始化共享数据目录
sudo /usr/local/bin/pfs -C disk mkdir /vdc/shared_data # 使用 pfs 创建共享数据目录
sudo $HOME/tmp_basedir_polardb_pg_1100_bld/bin/polar-initdb.sh $HOME/primary/ /vdc/shared_data/ # 初始化 db 的本地和共享数据目录
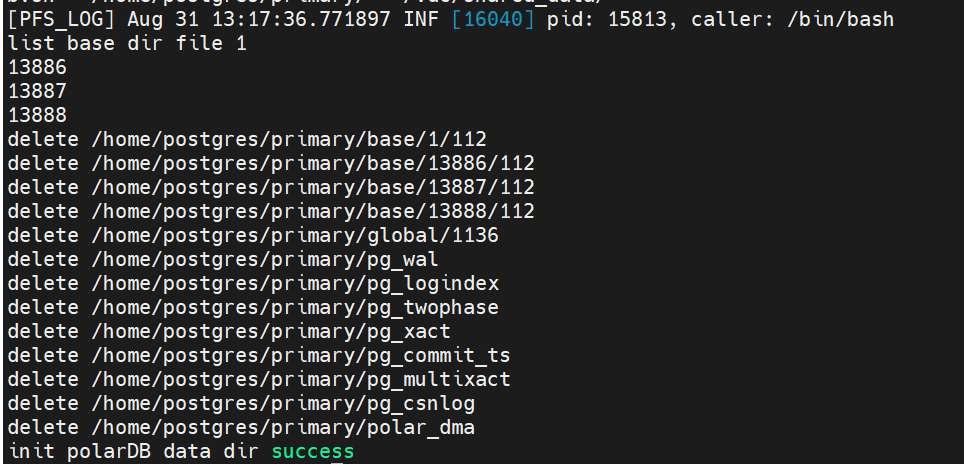
2.3 编辑读写节点的配置
$HOME/primary/postgresql.conf
添加下方文本内容,同时注意修改polar_disk_name、polar_datadir、synchronous_standby_names
port=5432 #不同机器上相同端口号,相同机器上不同端口号(5433,5434)
polar_hostid=1 #不同节点上编号不同 1,2,3,...,读写节点编号为1
polar_enable_shared_storage_mode=on
polar_disk_name='nvme1n1' #需要修改成空闲磁盘名vdc
polar_datadir='/nvme1n1/shared_data/' #需要修改成空闲磁盘名vdc
polar_vfs.localfs_mode=off
shared_preload_libraries='$libdir/polar_vfs,$libdir/polar_worker'
polar_storage_cluster_name='disk'
logging_collector=on
log_line_prefix='%p\t%r\t%u\t%m\t'
log_directory='pg_log'
listen_addresses='*'
max_connections=1000
synchronous_standby_names='replica1,replica2' #有几个只读节点就写几个replica,如果有三个只读节点,那就是'replica1,replica2,replica3'
$HOME/primary/pg_hba.conf中添加行
host replication postgres 0.0.0.0/0 trust
2.4 启动读写节点
$HOME/tmp_basedir_polardb_pg_1100_bld/bin/pg_ctl start -D $HOME/primary
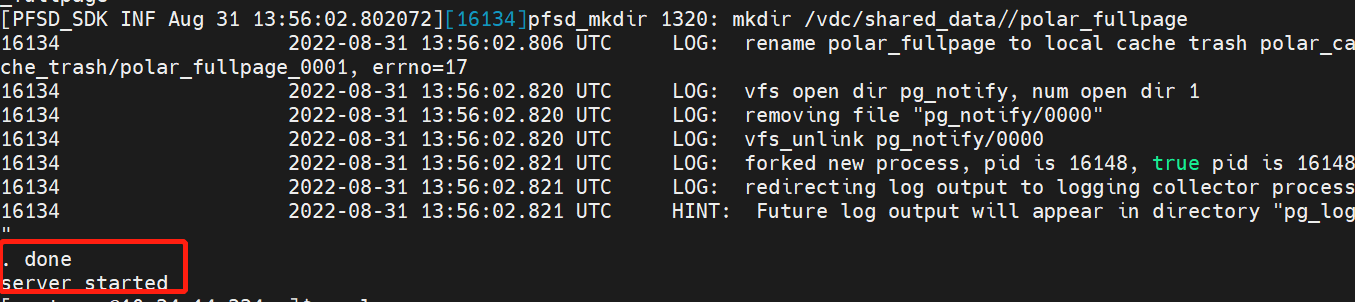
2.5 检查读写节点
psql
\l
create database t;
\l
\c t;
create table t1(k int);
\d
insert into t1 values(1);
select * from t1;
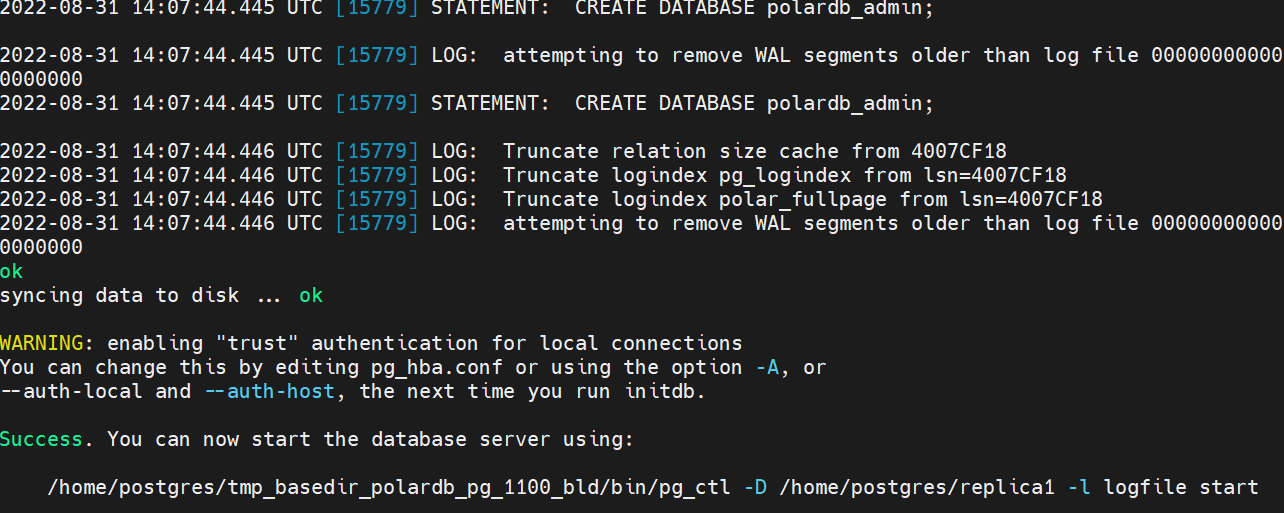
2.6 为对应的只读节点创建相应的 replication slot
创建相应的 replication slot,用于只读节点的物理流复制,必须逐个进行replica slot的创建
$HOME/tmp_basedir_polardb_pg_1100_bld/bin/psql \
-p 5432 \
-d postgres \
-c "select pg_create_physical_replication_slot('replica1');"
$HOME/tmp_basedir_polardb_pg_1100_bld/bin/psql \
-p 5432 \
-d postgres \
-c "select pg_create_physical_replication_slot('replica2');"
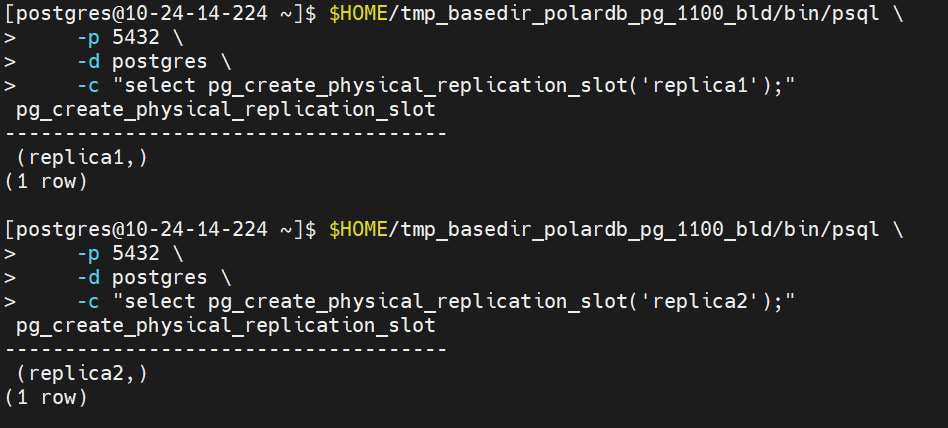
3. 配置只读节点
假设有两个只读节点,分别初始化数据目录replica1和replica2,初始化需要定期更新
3.1 初始化数据目录$HOME/replica1/,$HOME/replica2/
$HOME/tmp_basedir_polardb_pg_1100_bld/bin/initdb -D $HOME/replica1
$HOME/tmp_basedir_polardb_pg_1100_bld/bin/initdb -D $HOME/replica2
3.2 编辑只读节点的配置
$HOME/replica1/postgresql.conf
添加下方文本内容,注意修改polar_hostid、polar_disk_name、polar_datadir
port=5432 #不同机器上相同端口号,相同机器上不同端口号(5433,5434)
polar_hostid=2 #不同节点上编号不同,第一个读节点为2,第二个为3,...
polar_enable_shared_storage_mode=on
polar_disk_name='nvme1n1' #需要修改成空闲磁盘名vdc
polar_datadir='/nvme1n1/shared_data/' #需要修改成空闲磁盘名vdc
polar_vfs.localfs_mode=off
shared_preload_libraries='$libdir/polar_vfs,$libdir/polar_worker'
polar_storage_cluster_name='disk'
logging_collector=on
log_line_prefix='%p\t%r\t%u\t%m\t'
log_directory='pg_log'
listen_addresses='*'
max_connections=1000
$HOME/replica1/recovery.conf
此文件为新建,注意修改primary_slot_name、primary_conninfo
polar_replica='on'
recovery_target_timeline='latest'
primary_slot_name='replica1'
primary_conninfo='host=[读写节点所在IP] port=5432 user=postgres dbname=postgres application_name=replica1'
3.3 启动只读节点
根据各个节点修改后运行
$HOME/tmp_basedir_polardb_pg_1100_bld/bin/pg_ctl start -D $HOME/replica1
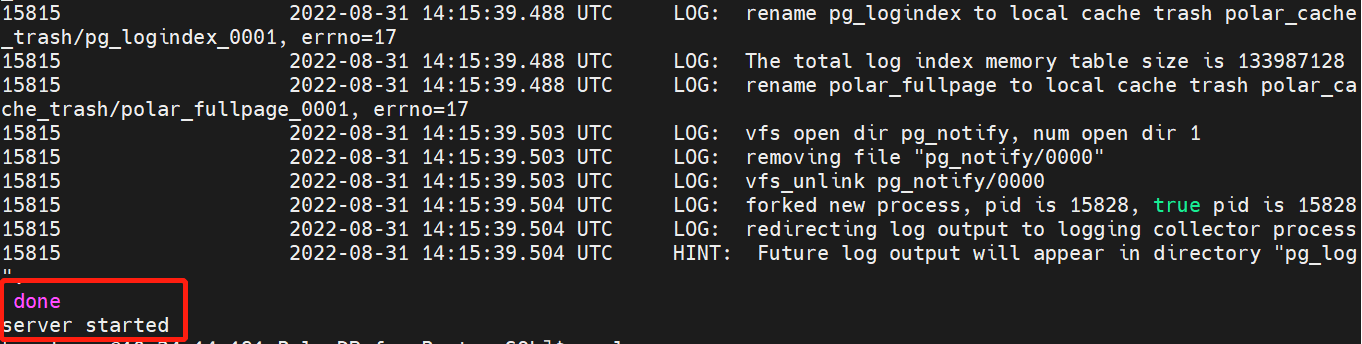
3.4 检查只读节点
作为只读节点,无法写入,主要检查两个:1、是否能看到读写节点上写下的数据2、在写入时是否能报不允许
psql
\l
\c t
\d
select * from t;
create table tt(k int);
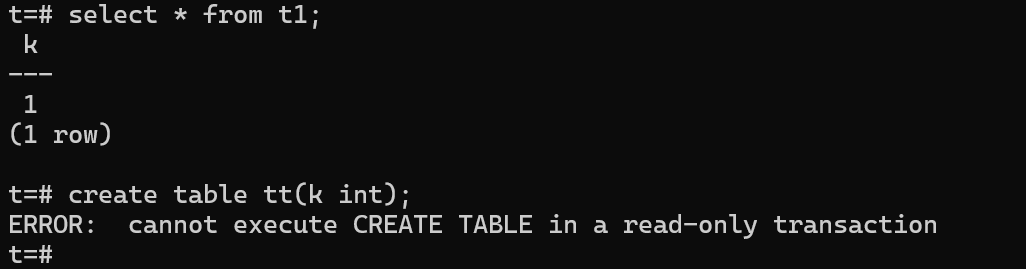 至此,三节点部署已完成
至此,三节点部署已完成
相关bug的可能解决方案
1. 主机没有网络,时钟不同步问题
1.1 开启ntpd服务
systemctl status ntpd
systemctl start ntpd
1.2 修改/etc/ntp.conf配置文件
修改在要对齐的主机上执行(授权 10.24.14.0-10.24.14.255 网段上的所有机器可以从这台机器上查询和同步时间),对下面这行取消注释
# restrict 10.24.14.0 mask 255.255.255.0 nomodify notrap
对下面这几行添加注释
server 0.centos.pool.ntp.org iburst
server 1.centos.pool.ntp.org iburst
server 2.centos.pool.ntp.org iburst
server 3.centos.pool.ntp.org iburst
添加以下行,当该节点无网络连接,使用本地时间作为时间服务器为其他节点提供时间同步
server 127.127.1.0 fudge 127.127.1.0 stratum 10
1.3 重启ntpd服务并设置开机自启
systemctl restart ntpd
systemctl enable ntpd
1.4 对其他机器的操作
关闭所有节点机器上的ntpd服务与自启动
sudo systemctl stop ntpd
sudo systemctl disable ntpd
所有节点机器设置定时任务1 分钟与时间服务器同步一次
sudo crontab -e
*/1 * * * * -b /usr/sbin/ntpdate 主机ip
sudo date
手动同步相关命令
sudo ntpdate 10.11.6.135
sudo ntpdate -s 10.11.6.135
sudo clockdiff 10.11.6.33
2. 磁盘格式化时出现正在使用,繁忙的问题
sudo dmsetup status
sudo dmsetup remove_all